MXFP4 in GPT-OSS : Why Everyone Talks About It
Recently in AI community, many people are excited about GPT-OSS. Not only because it is open source, but also because it uses a new number format called MXFP4 (Micro-scaled FP4). This makes the model much smaller in memory, so even very big models can run on normal GPUs. What is more, researches now start to use FP4 not only for inference, but also for training, which before was very hard.
What is MXFP4?
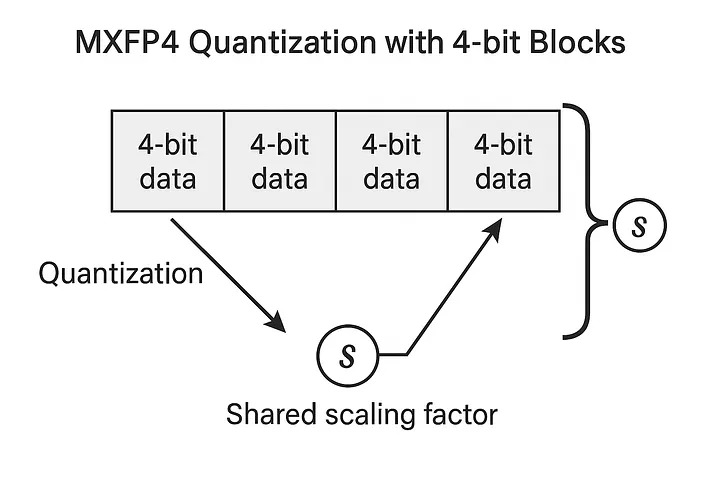
- FP4 basics: FP4 is a 4-bit floating point number. Normally 4 bits is too small, you lose a lot of precision.
- Micro-scaling idea: MFXP4 fixes this by grouping numbers intal small blocks (like 32 values, or 16 in NVFP4) and giving each block its own scale. This way, the numbers don’t lose range too quickly.
- Why it matters: Using FP4 reduces memory a lot. Compared to BF16 you save ~4× memory, and compared to FP8 it’s about 2×.
GPT-OSS using MXFP4
OpenAI released GPT-OSS-120B and GPT-OSS-20B with weights already in MXFP4.
- The 120B model can run on about 80 GB GPU memory.
- The 20B version fits in only 16 GB which even can be run on my local desktop (I have 5070TI which has 16GB VRAM). That is crazy small compared to normal large models. GPT-OSS also uses Mixture-of-Experts (MoE) and Grouped MQA, so it is very efficient.
However, GPT-OSS was not trained fully in FP4. It was trained with higher precision, then converted to MXFP4 for release. The research part now is how to really train in FP4 end to end.
FP4 for Training
Before, people only used FP4 for inference. Training was too unstable. But now we see progress:
- Fine-tuning while keeping FP4
- NVIDIA shows a recipe: upcast to BF16, fine-tune, then quantization-aware training (QAT) to go back to FP4.
- LMSYS and Unsloth also made guides to fine-tune GPT-OSS in FP4 on normal GPUs.
- Full FP4 training (still research)
- New tricks like stochastic rounding (avoid bias in gradients) help stability.
- Some papers show FP4 training can reach almost same accuracy as FP8, but with 2× faster GEMM speed.
- For vision models, methods like Q-EMA and Q-Ramping reduce oscillation problems.
- NVIDIA Blackwell GPUs (5000 models) even support NVFP4 natively, with smaller block size and better precision.
Why It Solves Memory Bottleneck
Big models are often blocked by memory and bandwidth, not just compute.
- Inference: FP4 makes parameters and KV cache much smaller.
- Training: Optimizer states, activations, gradients take huge memory. If they also move to FP4 (with tricks like error feedback), you can train bigger models or larger batch size on same GPU.
Still Some Problems
- Some tasks (math, code, reasoning) are more sensitive to low precision.
- Not all frameworks support MXFP4/NVFP4 yet. Sometimes only weights are FP4 but activations still higher precision.
- No public model is fully pretrained in FP4 yet, only research results.
My Thoughts
GPT-OSS made FP4 real for the community. Before, FP4 was more like an academic idea. Now people can actually run a 120B parameter model on one 80 GB GPU. That is impressive. The next step is full training in FP4, and we already see good progress.
If FP16 made deep learning practical, and BF16 made LLM training possible, then maybe FP4 will be the format that makes trillion parameter models possible for everyone.