Seq2Seq
기본 구조
- encoder와 decoder로 두 파트로 이루어져 있다.
- 각 파트는 서로 다른 RNN이다.
- 즉, 인코더와 디코더의 weight값은 다르다는 것이다.
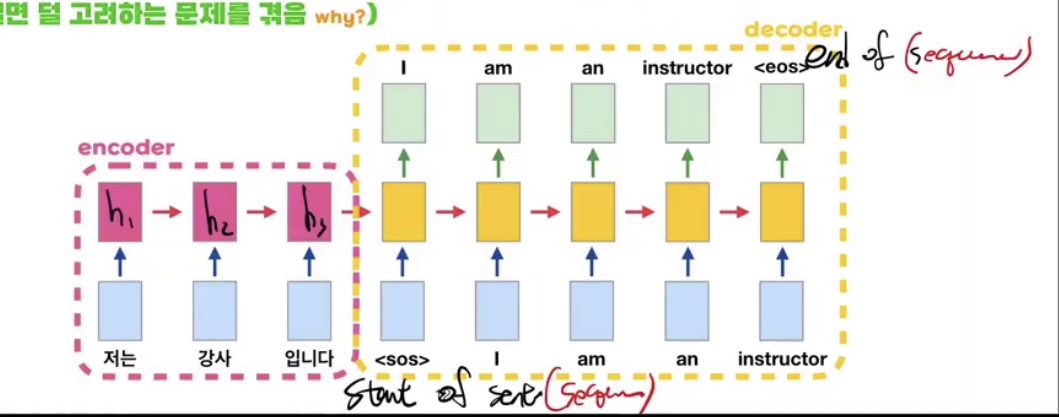
- 위 그림은 seq2seq의 기본 구조 예시이며 sos와 eos는 각각 start of sentence그리고 end of sentence를 의미한다.
- decoder는 next token prediction의 형태로 이루어져 있으며 학습 시에는 정답을 input 으로 넣어주며 지도 학습 혹은 teacher forcing으로 인해 학습이 되는 반면 테스트 시에는 출력 값이 입력으로 그대로 들어간다.
- encoder는 인풋 문장의 데이터를 학습하는 단계로써 마지막 h는 context vector로써 decoder의 첫 h 벡터로 사용되게 된다.
- seq2seq의 cell은 우리가 아는 plain RNN 구조가 아니라 LSTM (Long Short Term Memory) 나 GRU (Gated Recurrent Unit)이 사용된다.
- 이들은 plain RNN과 달리 밸브 시스템을 도입하여 short term와 long term의 정보에 가중치를 더해 특정 단어에 더 집중하자 라는 원리로 만들어진 구조이다.
- 하지만 이 구조 또한 멀면 정보가 흐려지는 문제점을 해결하지 못했다.
seq2seq의 단점
- 인코더나 디코더나 멀수록 잊혀지는 문제가 있다.
- context vector에는 인코더의 마지막 단어의 정보가 가장 뚜렷하게 담겨져 있다.
- 즉, 디코더는 마지막 단어를 제일 열심히 보며 next token prediction이 진행된다.