RNN (Recurrent Neural Network)
RNN의 사용 환경
- RNN은 시계열 데이터 즉, 순서가 있는 데이터에 적합한 네트워크 구조이다.
- RNN은 MLP를 기반으로 하여 Recurrent 즉, 입력 값마다 같은 네트워크를 순회하여 출력 값을 학습하는 방식이다.
RNN 구조
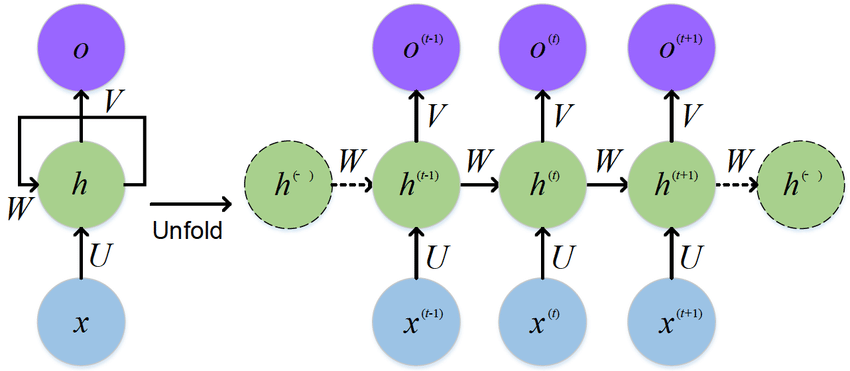
- 해당 그림이 RNN의 기본 구조라고 보면 된다.
- 예를 들어 $x_0, x_1, x_2$라는 세개의 입력 값이 있다고 하자.
- MLP를 통과한다고 하였을 때 $tanh(x_0W_x+b_x) = h_0$ 라는 수식을 가지게 될 것이다.
- 그다음 $x_1$은 다음과 같이 네트워크를 통과한다.
- $h_1 = \tanh(x_1W_x+h_0W_h+b_x)$
- 기존 MLP와 달리 이전 입력 값의 hidden state 즉, $h_{t-1}$도 네트워크에 포함시킨다.
- 더 나아가 $x_2$는 다음과 같은 식을 가지게 된다.
- $h_2 = \tanh(x_2W_x+h_1W_h+b_x)$
- 이후 최종 출력 값은 다음과 같다.
- $\hat y = h_2W_y+b_y$
- 활성화 함수를 통과하는 경우도 있고 통과하지 않는 경우도 있다고 한다.
Weight 및 Bias의 재사용
- 위의 RNN 연산 식을 보았을 때 $W_x,W_h,W_y,b_x,b_y$는 입력 값마다 달라지는 것이 아니라 다음 단계로 나아가서도 같은 변수를 사용한다.
- 즉, 시점에 따라 Weight가 달라지는 것이 아니라 같은 Weight를 재사용한다는 것이다.
- 물론 Back Propagation으로 학습할 때에는 값에 변화가 생긴다.
- 하지만 만약 재사용을 하지 않는다면 어떻게 될까?
- 예를 들어 입력 값이 3개였으니까 각 값마다 3개의 weight가 따로 존재한다고 해보자.
- 여기서 입력 값은 토큰 이며 토큰은 문장의 단어라고 생각하면 된다.
- 만약 단어가 4개인 문장이 입력이면 추가로 weight가 생성이 되어야하는데 이에 대한 학습을 추가로 해야된다.
- 즉, 단어가 3개인 문장 밖에 해당 RNN에는 적용된다는 것이다.
- 그렇기에 RNN은 같은 weight를 사용하며 입력 길이의 가변성을 보장해준다.
과거 정보 유지
- 이건 또다른 RNN의 장점인데 RNN은 이전 state의 $h$값을 가져오는 것을 볼 수 있다.
- 해당 과정을 통해 이전 입력 값의 정보를 가져오며 다음 단어를 예측하는데에 도움을 줄 수 있다.