Pre-Activation ResNet(2016.7)
등장 배경
- Identity Mapping에 대한 더욱 깊은 이해를 하고자 그에 관한 연구를 하던 중 vanishing gradient를 해결할 수 있는 방안을 내놓았다.
- Identity Mapping으로 인해 전달되는 값이 순전파 및 역전파 과정 중 손실 없이 전달된다면 더욱 성능을 끌어올리고 훈련 속도도 더 빨라질 수 있다는 결론에 다다랐다.
- 위의 과정을 위해서 떠올린 아이디어가 Pre-Activation이다.
논문 출처
1603.05027
기존 Residual Block의 구조
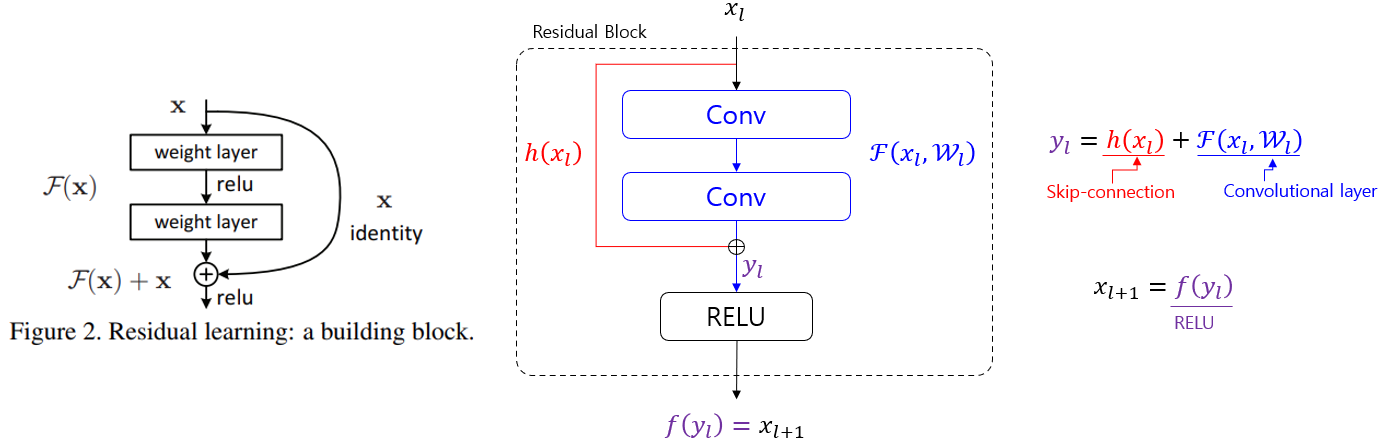
- 기존 ResNet에선 위와 같이 Conv 블럭을 통과하고 나온 값이 identity mapping 값과 더해진 다음 ReLU 함수를 통과한다.
- 식으로 나타내자면…
- $x_{l+1} = ReLU(h(x_l)+F(x_l, W_l))$
- 해당 구조가 역전파를 통과하게 되면 ReLU의 미분 값이 포함이 되어 그라디언트가 손실이 된다.
- ReLU의 미분 값은 0 혹은 1이기 때문이다.
활성화 함수가 Identity Mapping이면?
- 만약 활성화 함수가 ReLU가 아니라 Identity Mapping이면 어떻게 될까?
- 위 그림을 참고하자면 $y_l = x_l+1$이 되기 때문에 $x_{l+1} = x_l+F(x_l, W_l)$ 이라는 식이 성립이 된다.
- 이후 해당 식이 역전파를 통과하게 되면 $x_l$에 대한 미분 값이 1로 고정이 되기에 $F(x_l,W_l)$의 미분 값이 -1이 되지 않는 이상 그라디언트가 손실 된 일이 없다.
- Conv Layer의 미분 값이 -1이 될 확률은 사실상 불가능에 가깝다.
- 데이터가 네트워크를 통과할 때 모든 데이터가 통과되는게 아니라 미니 배치 형식으로 통과되기에 모든 배치의 미분 값이 -1이 되지 않는 이상 $F(x_l,W_l)$의 미분 값이 -1이 될 확률은 없다.
- 즉, 활성화 함수가 identity mapping이면 vanishing gradient 문제를 해결 할 수 있다.
어떻게 활성화 함수를 Identity Mapping으로 만들까?
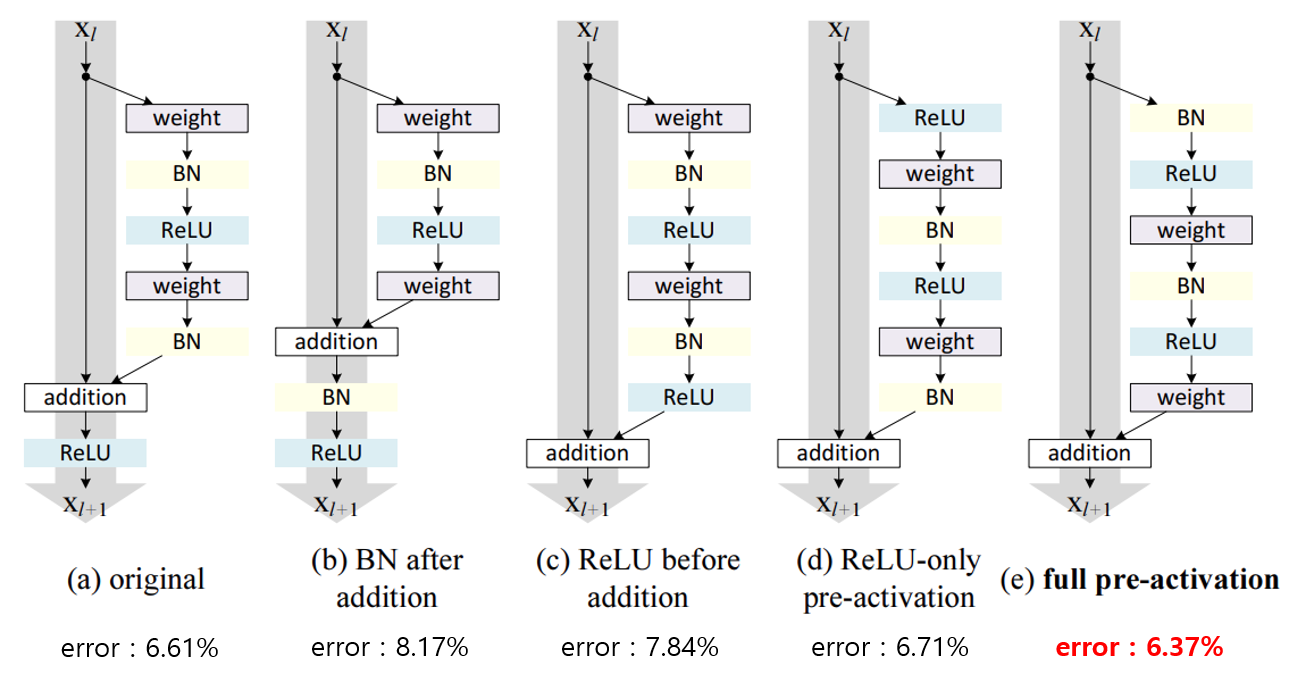
- 논문에서는 활성화 함수를 identity mapping으로 만들기 위해 여러 구조를 테스트 해보았다.
- (c) 구조가 우리가 보기엔 가장 그럴듯 해보이지만 성능이 기존 구조보다 높게 나오지가 않았다. 해당 이유는 Conv Layer를 통과한 이후 ReLU를 통과하면서 신호 값이 양수로만 제한되기 때문에 표현력이 줄어들어 성능이 줄어들기 때문이다.
- 이후 제안 된 것이 (e) 구조이며 해당 구조는 우리의 목표도 달성하고 성능도 기존 구조보다 향상되었다.
- 다음과 같이 Conv 이전에 ReLU와 BN이 들어가기에 해당 구조의 모델을 Pre-Activation ResNet이라고 부른다.