MobileNet V3
MobileNet V3 (2019.05)
등장 배경
- 기존 MobileNet V2에서 SE 블록을 추가하고 Swish 활성화 함수를 사용하면서 더더욱 모바일 및 임베디드 환경에 최적화를 진행하였다.
- 또한 AutoML 중 하나인 NAS (Neural Architecture Search)를 사용하여 latency를 더욱 최소화 할 수 있는 최적의 네트워크 구조를 마련하였다.
논문 출처
SE Block의 도입
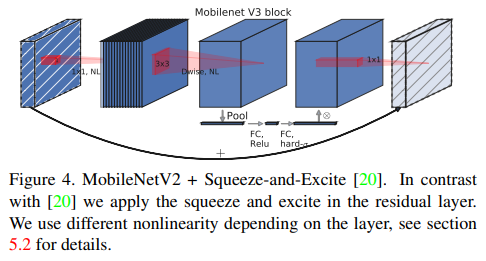
- MobileNet V3에서의 메인 차이점 중 하나는 SE Block의 도입이다.
- SE 연산은 Depth-wise Convolution 이후에 적용이 되며 성능을 끌어올려주었다.
- 이때 사용 된 reduction ratio는 4이며 실험을 통해 r = 4일때 성능이 가장 잘 나왔다고 한다.
- reduction ratio란 SE 파트에서 Excitation 과정 도중 MLP를 거칠 때 채널이 줄어드는 배수를 뜻한다.
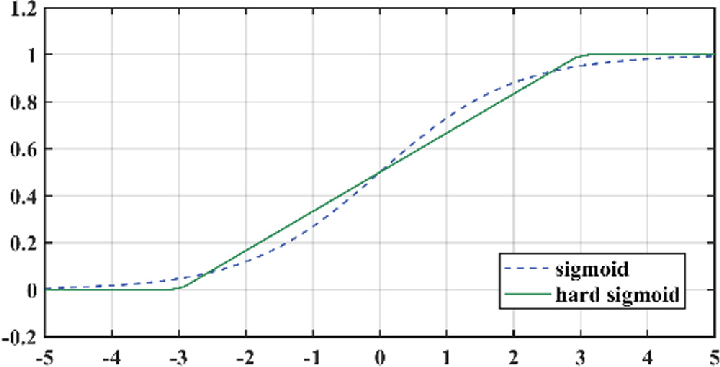
- 또한 원래는 MLP에서 ReLU와 Sigmoid가 활성화 함수로써 사용되었는데 모바일 환경에 더욱 특화되도록 hard-sigmoid 함수를 사용하였다. 이에 관해서는 후술하도록 하겠다.
Hard Activation Functions
- 일단 Swish 라는 활성화 함수에 대해 먼저 알아야 한다.
- Swish = $x \cdot ReLU(x)$ 이며 이는 다음과 같은 형태를 띄운다.
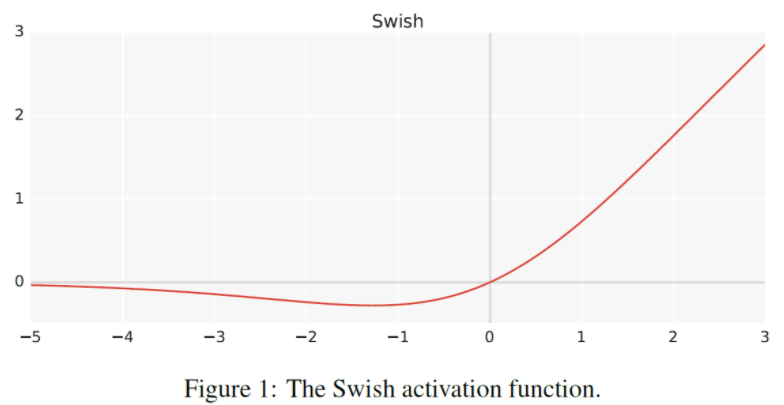
- 정확한 이유는 설명되어있지 않지만 ReLU보다 성능이 더 뛰어나다고 한다.
- Swish 같은 경우 MobileNet V3에서 모든 ReLU를 대체하지는 않지만 종종 사용된다.
- 하지만 논문 저자는 Swish를 모바일 환경에 맞도록 새로운 형태의 Swish를 제안한다.
- 이는 Hard Swish 혹은 H-Swish라고 불리며 함수를 더욱 심플한 형태로 바꾸어 메모리 접근 수도 줄이고 양자화 모드에서 정확도 손실을 줄여준다고 한다.
- H-Swish = $x \cdot \dfrac{ReLU(x+3)}{6}$ 이며 다음과 같은 형태를 띄운다.
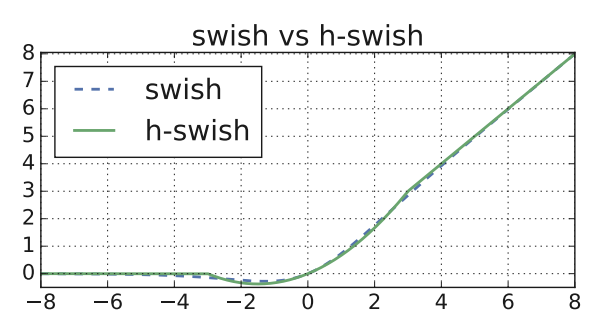
- 보이다 싶이 기존 Swish와의 큰 차이가 없어 성능 부분에서도 손실될 부분이 매우 적다.
- 여기서 영감을 얻어 SE에 사용되는 sigmoid도 hard sigmoid로 변환하여 사용을 한다.
- H-Sigmoid = $\dfrac{ReLU(x+3)}{6}$
Neural Architecture Search (NAS)
- MobileNet V3는 구조의 틀을 짜기 위해 AutoML 기법인 NAS를 사용하여 구조를 만들었다.
- NAS에 대해서는 여기서 자세히 서술하기엔 너무 광범위하기에 컨셉만 설명하고 넘어가도록 하겠다.
- NAS는 기준점을 넣어주면 해당 기준에 맞게 최적화된 모델 구조를 만들어주는 AutoML이다.
- 해당 논문에선 accuracy와 latency에 기준을 두고 둘의 밸런스를 유지하며 최적화된 구조를 만들어내도록 하였다.
입출력 구조의 변경
- 먼저 NAS에서의 결과물에서 지연시간을 더욱 줄이기 위해 입력 구조를 저자들은 바꾸었다.
- 3채널짜리 이미지 입력 값을 받고 32채널로 Convolution 하는 구조를 NAS는 만들어냈지만 이는 중복된 채널을 많이 만들어낸다는 것을 알아내어 16채널로 줄여 보니 성능의 차이가 없어 첫 Convolution은 16채널로 진행하였다.
- 이후 출력 구조에서도 변화를 주었다.
- 보통 GAP 이전에 1x1 Conv를 사용하여 고차원의 feature로 확장 시키는데 이는 7x7 Feature map에서 진행되다 보니 지연시간이 대폭 늘어나게 된다.
- 그렇기에 GAP 이후에 1x1 Conv를 사용하여 7x7이 아닌 1x1 Feature map에서 연산이 진행되어 연산 시간이 대폭 줄어들게 된다.
전체 구조
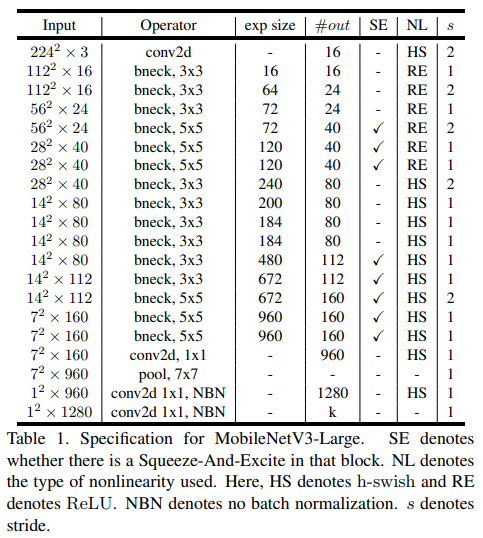
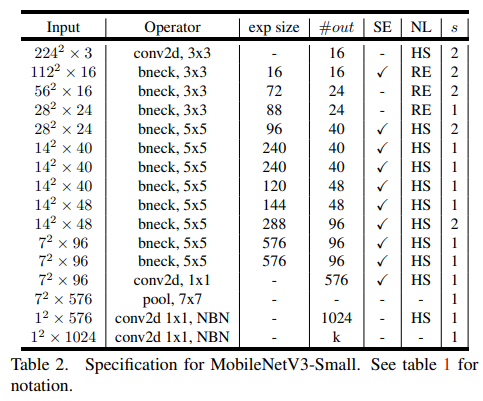
- 논문에서는 Large 모델 (왼쪽 테이블)과 Small 모델 (오른쪽 테이블) 두가지 구조를 제시했는데 이는 사용되는 환경의 resource에 따라 선택하면 된다고 한다.
- 보이다 싶이 SE가 사용되는 곳도 있고 아닌 곳도 있고 ReLU6가 아닌 ReLU를 사용한다.
코드 구현
-
make_divisible 함수
def _make_divisible(v, divisor, min_value=None): """ This function is taken from the original tf repo. It ensures that all layers have a channel number that is divisible by 8 It can be seen here: https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py :param v: :param divisor: :param min_value: :return: """ # 쉽게 말해, 이 함수는 가까운 8의 배수를 찾아줌 if min_value is None: min_value = divisor new_v = max(min_value, int(v + divisor / 2) // divisor * divisor) # divisor / 2 는 반올림을 위해 (너무 작아지지 않게) # case 1) v=10, divisor = 8 이면 10+4 // 8 * 8 = 8 근데 10 => 8 은 10% 이상 빠지는 거니까 8+8 = 16 으로 조정됨 # case 2) v=39, divisor = 8 이면 39+4 // 8 * 8 = 40 => 10%보다 빠지지 않았기 때문에 40이 출력됨! if new_v < 0.9 * v: # 10% 보다 더 빠지지 않게 조정 new_v += divisor return new_v- MobileNet V3에서는 채널 수가 8의 배수로 고정되기에 Inverted Bottleneck 통과 이후 채널 수가 8의 배수가 아닐 때 가까운 8의 배수로 조정하는 함수이다.
-
SE Block 클래스
class SEBlock(nn.Module): def __init__(self, in_channels, r = 4): # mobilenet V3 에서는 reduction ratio r=4로! super().__init__() self.squeeze = nn.AdaptiveAvgPool2d((1,1)) self.excitation = nn.Sequential(nn.Linear(in_channels, _make_divisible(in_channels // r, 8)), nn.ReLU(inplace=True), nn.Linear(_make_divisible(in_channels // r, 8), in_channels), nn.Hardsigmoid(inplace=True)) # Hard sigmoid! def forward(self, x): SE = self.squeeze(x) SE = SE.reshape(x.shape[0],x.shape[1]) SE = self.excitation(SE) SE = SE.unsqueeze(dim=2).unsqueeze(dim=3) x = x * SE return x- SENet 논문에서 구현해놓은 코드와 크게 다른 점은 없지만 Sigmoid가 아니라 Hard Sigmoid가 적용된 모습을 볼 수 있다.
- 또한 위에서 서술한 make_divisible 함수가 채널 수에 적용된 것을 볼 수 있다.
-
DepSESep 클래스
class DepSESep(nn.Module): def __init__(self, in_channels, out_channels, kernel_size, use_se, use_hs, stride): super().__init__() self.depthwise = nn.Sequential(nn.Conv2d(in_channels, in_channels, kernel_size, stride = stride, padding = (kernel_size - 1) // 2, groups = in_channels, bias=False), nn.BatchNorm2d(in_channels, momentum=0.99), # momentum = 0.99 는 논문에서 제시 nn.Hardswish(inplace=True) if use_hs else nn.ReLU(inplace=True)) # hs 아니면 걍 ReLU (ReLU6 아님) self.seblock = SEBlock(in_channels) if use_se else None self.pointwise = nn.Sequential(nn.Conv2d(in_channels, out_channels,1, bias=False), nn.BatchNorm2d(out_channels, momentum=0.99)) # no activation!! def forward(self, x): x = self.depthwise(x) if self.seblock is not None: x = self.seblock(x) x = self.pointwise(x) return x- Depth-wise Separable Convolution을 담당하는 클래스이다.
- use_hs와 use_se를 어트리뷰트로 받아 활성화 함수의 종류와 SE 사용 여부를 결정하여 블록의 구조를 바꾼다.
- use_hs와 use_se는 나중에 list 형식으로 config 변수에 들어있을 예정이다.
-
InvertedBlock 클래스
class InvertedBlock(nn.Module): def __init__(self, in_channels, exp_channels, out_channels, kernel_size, stride, use_se, use_hs): super().__init__() self.use_skip_connect = (stride==1 and in_channels==out_channels) layers = [] if in_channels != exp_channels: # 채널 안늘어날 때는 1x1 생략. 즉, 1x1은 채널을 키워야할 때만 존재한다. layers += [nn.Sequential(nn.Conv2d(in_channels, exp_channels, 1, bias=False), nn.BatchNorm2d(exp_channels, momentum=0.99), nn.Hardswish(inplace=True) if use_hs else nn.ReLU(inplace=True))] layers += [DepSESep(exp_channels, out_channels, kernel_size, use_se, use_hs, stride=stride)] self.residual = nn.Sequential(*layers) def forward(self, x): if self.use_skip_connect: return x + self.residual(x) # 더하고 ReLU 하지 않는다! 그래야 linear block이 되는 거니까 else: return self.residual(x)- V2와 큰 차이점은 없다.
- 단지 활성화 함수의 종류가 다양해졌을 뿐이다.
-
MobileNetV3 클래스
class MobileNetV3(nn.Module): def __init__(self, cfgs, last_channels, num_classes=1000, width_mult=1.): super().__init__() in_channels = _make_divisible(16 * width_mult, 8) # building first layer self.stem_conv = nn.Sequential(nn.Conv2d(3, in_channels, 3, padding=1, stride=2, bias=False), nn.BatchNorm2d(in_channels, momentum=0.99), nn.Hardswish(inplace=True)) # 처음건 무조건 HS, HS를 써서 16으로 줄일 수 있었다 함 # building inverted residual blocks layers=[] for k, t, c, use_se, use_hs, s in cfgs: exp_channels = _make_divisible(in_channels * t, 8) out_channels = _make_divisible(c * width_mult, 8) layers += [InvertedBlock(in_channels, exp_channels, out_channels, k, s, use_se, use_hs)] in_channels = out_channels self.layers = nn.Sequential(*layers) # building last several layers self.last_conv = nn.Sequential(nn.Conv2d(in_channels, exp_channels, 1, bias=False), nn.BatchNorm2d(exp_channels, momentum=0.99), nn.Hardswish(inplace=True)) self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) last_channels = _make_divisible(last_channels * width_mult, 8) self.classifier = nn.Sequential(nn.Linear(exp_channels, last_channels), nn.Hardswish(inplace=True), nn.Dropout(p=0.2, inplace=True), nn.Linear(last_channels, num_classes)) # MLP 부활 for m in self.modules(): if isinstance(m, nn.Conv2d): nn.init.kaiming_normal_(m.weight, mode="fan_out") if m.bias is not None: nn.init.zeros_(m.bias) elif isinstance(m, nn.Linear): nn.init.normal_(m.weight, 0, 0.01) nn.init.zeros_(m.bias) def forward(self, x): x = self.stem_conv(x) x = self.layers(x) x = self.last_conv(x) x = self.avgpool(x) x = torch.flatten(x, 1) x = self.classifier(x) return x