WideResNet
WideResNet (WRN) (2017.01)
등장 배경
- 해당 논문이 나올 시기엔 AlexNet을 시작으로 VGGNet, Inception, ResNet 등 CNN을 깊게 만들고 이에 따라 발생하는 vanishing/exploding gradient나 degradation 문제를 해결하는데에 집중하였다.
- 하지만 CNN을 깊게 만들며 급속도로 증가하는 computational cost를 쉽게 고치기는 어려웠다. 이미 여러 방안들이 나왔고 완전히 새로운 접근법이 나오지 않고서는 더이상의 성능 개선을 기대하기는 어려웠다.
- 해당 시기에 SOTA 모델에 등극했던 모델은 pre-activation ResNet이었다. 해당 모델은 기존의 activation 순서였던 Conv ⇒ BN ⇒ ReLU를 BN ⇒ ReLU ⇒ Conv. 로 바꾸면서 성능의 향상을 만들었다.
- 이 시기에 또 다른 역발상을 하여 CNN을 깊게 만드는게 아니라 얇고 넓게 만든 모델이 WRN 이다.
논문 출처
Circuit Complexity Theory
- 그렇다면 왜이리 학자들은 CNN을 깊게 만드는 것에 혈안이 되있을까?
- Circuit Complexity Theory란, shallow circuit은 deep circuit의 성능을 따라오려면 더더욱 complex해져야 된다는 이론이다.
- 이에 따라 shallow하게 모델을 만들면 그에 따라 parameter 수가 급증할 것이고 이것은 computational cost를 너무나 많이 잡아먹기에 deep한 모델을 더욱 추구한 것이다.
- 하지만 WRN은 16층의 깊이를 가지면서 1000층의 기존 ResNet를 웃도는 성능을 보여주어 해당 이론에 학자들이 너무 사로잡혀있었다는 것을 보여준다.
Deep Network의 폐착
- Diminishing Feature Reuse
- 해당 문제는 vanishing gradient의 순전파 버전이라고 보면 되는데 순전파에서 입력 층의 값이 출력 층까지 도달하지 못하는 문제이다.
- 해당 문제는 당연하게도 층이 너무 깊어져 가중치끼리 너무나 많이 곱해져 점점 입력층의 값이 잊혀지는 것이다.
- Residual Block
- Residual Block은 ResNet의 장점이면서도 단점이다.
- Skip-Connection을 도입하면서 급격하게 값의 변화를 주는 것이 아니라 천천히 값을 변화시켜나가는 형태는 좋은 접근이었다. 하지만 해당 방법은 학습의 강제성을 너무나 줄여서 학습의 속도가 너무 느리다는 것이다. 즉, 층이 깊어져도 성능의 개선이 너무나 느리게 이루어진다.
해결 방안
- Diminishing Feature Reuse의 해결 방안
- 본래 위의 문제를 해결하기 위해 특정 residual block 자체를 일정 확률로 없애는 방식으로 일종의 dropout이 적용이 되었다.
- 하지만 해당 방법은 문제를 해결하지 못하였고 WRN은 새로운 드롭아웃의 방식을 채택했다.
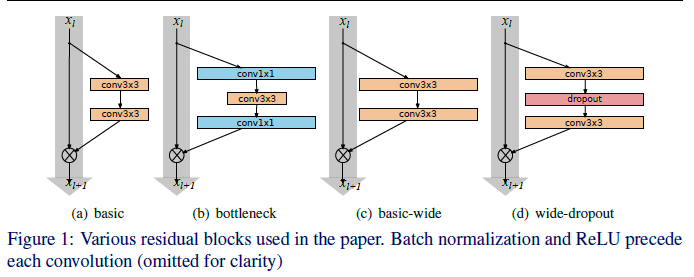
- 맨 우측에 보이는 대로 conv 레이어 사이에 dropout을 적용시켜 입력 값이 잊혀지는 것을 방지하는 것이다.
- 또한 WRN의 가장 기본이 되는 개념인 deeper보단 wider하게 모델을 만들면 가중가 곱해지는 횟수가 덜해 입력값이 덜 잊혀질 것이다.
- Residual Block의 해결 방안
- 모델을 wide하게 만들면서 residual block에 할당되는 파라미터의 수가 기존 ResNet보다 훨씬 증가하게 되면서 skip-connection이 들어가도 본래 residual block의 weight가 학습이 되지 않는 문제가 줄어들며 Residual Block의 단점을 보완하였다.
WRN의 구조
- 생각보다 WRN의 구조는 단순하다.
- 일단 Residual Block의 구조는
- 위 그림의 (d)의 해당되는 구조를 채택하였다.
- Bottleneck 구조는 기존 ResNet에서 thin한 모델을 만들며 파라미터의 갯수를 줄이기 위해 도입된 것이므로 채용하지 않았다.
- 또한, pre-activation ResNet의 구조에 따라 BN ⇒ ReLU ⇒ Conv. 의 순서를 채택하였다.
- 이후 Block 안에 몇개의 conv 레이어가 들어갈까에 대한 실험도 진행하였는데 밑의 그림과 같이 $l = 2$ 즉, 2개의 conv가 있는 것이 성능이 가장 잘 나왔다.
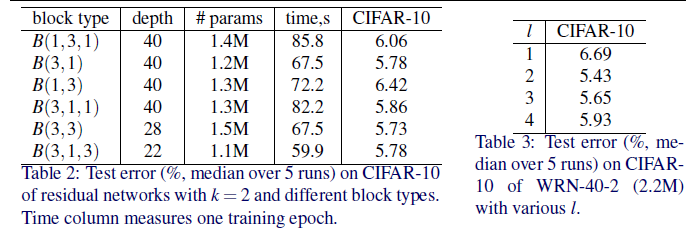
-
전체적인 모델의 구조는…
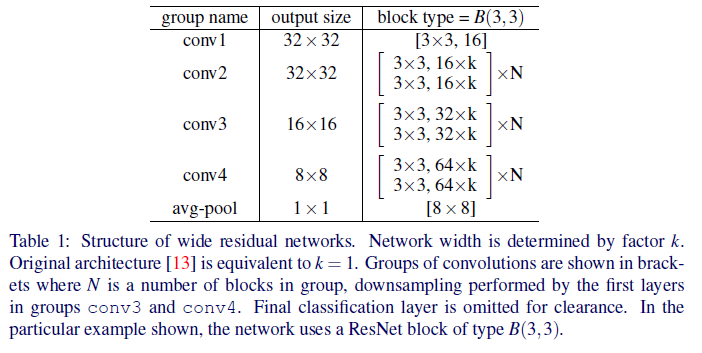
- 총 4개의 블럭으로 이루어져 있으며 $k$는 width를 담당하는 factor이며 $N$은 depth를 담당하는 factor이다.
- 보통 WRN은 $WRN-N-k$ 형식으로 표기하며 WRN-16-3이면 16층이며 채널의 수가 3배가 된 WRN이라고 생각하면 된다.
- N과 k의 값은 데이터셋마다 상이하며 대표적인 CIFAR, SVHN, COCO, ImageNet에서의 실험 결과는 논문에 있으니 참고하면 될 것 같다.
Conclusion
- 모델을 widen하는 것은 어느 깊이이든 성능 향상을 보여준다.
- 강력한 regularizer가 필요하기 전에는 width와 depth 모두 증가하는 것이 성능 향상에 도움이 된다.
- 너무나 깊은 ResNet은 regularizer의 힘을 잃어버리기에 적당한 깊이에 width를 증가시키는 것이 도움이 될 것이다.
코드 구현
class WiderBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, projection=None, drop_p=0.3):
# drop_p = 0.3 for CIFAR, 0.4 for SVHN
super().__init__()
self.residual = nn.Sequential(nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels, out_channels, 3, stride=stride, padding=1, bias = False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Dropout(drop_p),
nn.Conv2d(out_channels, out_channels, 3, padding=1, bias = False))
self.projection = projection
def forward(self, x):
residual = self.residual(x)
if self.projection is not None:
shortcut = self.projection(x)
else:
shortcut = x
out = residual + shortcut # 엉! ReLU 였는데 ReLU 없음!
return out
class WRN(nn.Module):
def __init__(self, depth, k, num_classes=1000, init_weights=True):
super().__init__()
N = int((depth-4)/3/2)
self.in_channels = 16
self.conv1 = nn.Conv2d(3, 16, 3, padding=1, bias = False)
# pre-act 구조에선 첫번째 conv block에서 pool 있으면 conv-BN-relu-pool -> Bottleneck 이렇게
# 이유는? 맨처음에 bn-relu를 통과시키면 데이터 전처리에서 할 일을 하게 되는 셈이다
# 근데 WRN 처럼 Block 들어가기 전 pooling이 없으면? conv -> Block 으로 바로 들어가는 듯 why?
# conv-bn-relu -> Block 으로 넣으면 Block 에서 bn-relu를 만나서 bn-relu-bn-relu 이렇게 돼버린다!
self.stage1 = self.make_stage(16*k, N, stride = 1)
self.stage2 = self.make_stage(32*k, N, stride = 2)
self.stage3 = self.make_stage(64*k, N, stride = 2)
self.bn = nn.BatchNorm2d(64*k)
self.relu = nn.ReLU(inplace=True)
self.avg_pool = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Linear(64*k, num_classes)
# weight initialization
if init_weights:
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.conv1(x)
x = self.stage1(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.bn(x)
x = self.relu(x)
x = self.avg_pool(x)
x = torch.flatten(x, start_dim=1)
x = self.fc(x)
return x
def make_stage(self, out_channels, num_blocks, stride):
if stride != 1 or self.in_channels != out_channels:
projection = nn.Conv2d(self.in_channels, out_channels, 1, stride=stride, bias = False)
# nn.BatchNorm2d(inner_channels * block.expansion)) # pre-act 라서 여기선 생략
else:
projection = None
layers = []
layers += [WiderBlock(self.in_channels, out_channels, stride, projection)] # stride=2, 점선 연결은 첫 block에서만
self.in_channels = out_channels
for _ in range(1, num_blocks):
layers += [WiderBlock(self.in_channels, out_channels)]
return nn.Sequential(*layers)
유의할 점
-
WRN Block에서의 Forward 함수
def forward(self, x): residual = self.residual(x) if self.projection is not None: shortcut = self.projection(x) else: shortcut = x out = residual + shortcut # 엉! ReLU 였는데 ReLU 없음! return out- 주석 처리가 되어있지만 WRN에선 pre-act의 구조를 사용하기에 residual과 입력 값을 더해줄 때 ReLU를 취하지 안하고 합한 값 그대로 리턴한다.
-
Conv Block
self.conv1 = nn.Conv2d(3, 16, 3, padding=1, bias = False) self.stage1 = self.make_stage(16*k, N, stride = 1) self.stage2 = self.make_stage(32*k, N, stride = 2) self.stage3 = self.make_stage(64*k, N, stride = 2)- Conv1 블럭을 보면 Conv 레이어 하나밖에 없는데 이에는 합당한 이유가 있다.
- 본래 pre-act에선 초기 Conv 에는 BN ⇒ ReLU를 도입하지 않는다. 왜냐하면 그렇게 되면 입력 이미지를 pre-process하는 것과 다를게 없기 때문이다.
- 그렇다고 원래 순서처럼 Conv ⇒ BN ⇒ ReLU를 하지 않는 이유는 다음 블럭이 BN⇒ReLU로 시작하기에 Conv⇒BN⇒ReLU⇒BN⇒ReLU가 되기 때문이다.
- 중간에 풀링이라도 있었다면 상관이 없었겠지만 WRN 논문에선 첫번째 블럭에서 풀링을 하지 않기에 Conv. 하나만 넣은 것이다.
- 이후 stage 1,2,3를 보면 stage 1만 stride=1인데 그 이유는 stage1에서만 점선 연결로 채널 수를 변경하고 (즉, 풀링을 한다는 것) 그 이후에는 stride=2로 채널 수를 조정한다.