VGGNet
VGGNet(2014.09)
요약
- VGGNet은 2014년 ILSVRC에서 2등을 차지한 딥 CNN 모델로, 3x3 필터를 사용하여 16~19층의 구조를 가지며, 다양한 구성을 통해 이미지 분류 성능을 개선한다. 손실 함수로 CrossEntropy를 사용하고, 데이터 증강 기법으로 FiveCrop을 활용하여 입력 이미지를 5배 증가시킨다.
등장 배경
- ILSVRC-2014 이미지넷 분류 대회에서 2등을 차지한 최초의 Deep CNN 인공 신경망 모델이다.
- VGGNet 이전에는 CNN을 깊게 만들려는 시도는 없었고 CNN의 개념이 생긴 지 얼마 안된 시기이다.
- 따지고 보면 AlexNet이 첫 시도였지만 8층이 한계였다.
- 같은 시기에 Inception Net (GoogLeNet)이 나왔는데 해당 모델이 ILSVRC-2014에서 1등을 차지했다.
논문 출처
- K. Simonyan and A. Zisserman. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv:1409.1556, 2014
초록
- 이 논문의 중점은 CNN의 깊이에 따른 이미지 분류 성능 개선의 여부 확인이다.
- 해당 모델은 가장 작은 사이즈의 필터 (3x3)을 사용하고 16~19층의 CNN 아키텍쳐를 사용하며 SOTA 성능을 가진 모델이다.
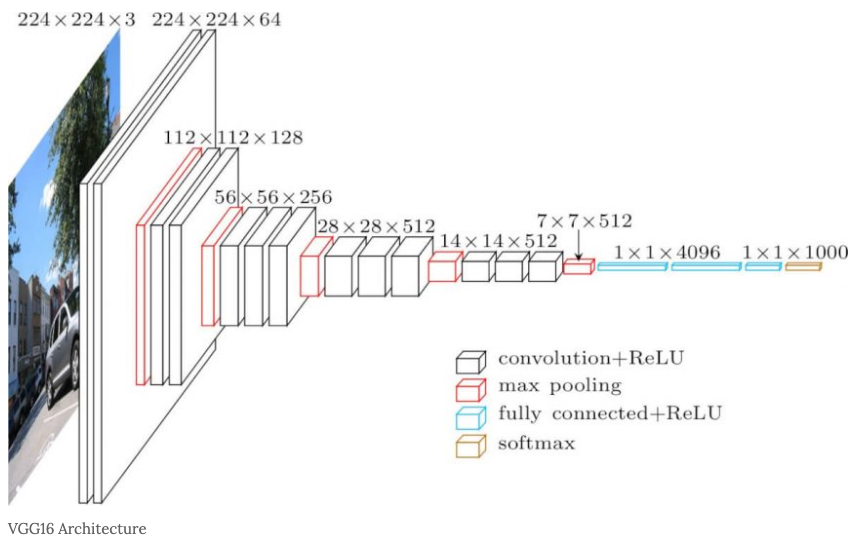
기본 구조
- 입력 이미지 데이터는 224x244 RGB 이미지로 한정.
- 필터 사이즈는 가장 작은 3x3으로 통일.
- 해당 논문은 총 5개의 configuration를 소개하며 그 중 하나는 1x1 필터를 포함.
- 입력 정보를 그대로 넘기며 비선형성을 증가시키려는 목적.
- 합성곱 이전과 이후의 피처 맵 사이즈를 동일하게 유지하기 위해 Stride = 1, Padding = 1으로 고정한다.
- 최대 풀링은 총 5번 시행하며 사이즈는 2로 고정하며 풀링을 통과할 때 마다 피처 맵의 사이즈가 반으로 줄어들도록 한다.
- 이후 FC 레이어를 통과하여 4096개의 출력으로 만들고 다시 한번 4096개의 출력 노드를 갖는 FC 레이어를 통과한다.
- 이후 1000개의 출력 노드가 나오게끔 FC 레이어를 통과하고 softmax를 통해 확률 값으로 나타낸다.
- ImageNet 기준이라 1000개로 출력 노드 갯수를 잡았다.
- 각 층 사이에는 ReLU 활성화 함수를 사용한다.
Configurations
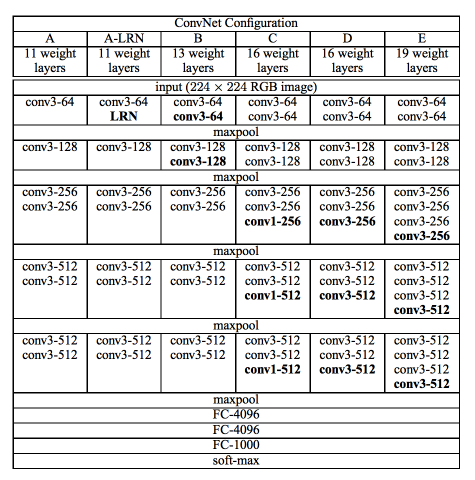
- VGGNet은 위와 같이 5개의 다른 구성을 가진 모델을 소개했다.
- A에서 E로 갈수록 층이 더 깊어지고 몇몇 구성은 LRN을 도입하거나 1x1 필터를 사용하였다.
- 참고로 1x1 필터를 사용하여 피처 맵을 건들지 않고 비선형성을 늘리는 아이디어는 ‘Network in Network’라는 논문에서 처음 제시된 개념이다.
- 코드 구현
cfgs = {
'A': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'B': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'D': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'E': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
class VGG(nn.Module):
def __init__(self, cfg, batch_norm, num_classes = 10, init_weights = True, drop_p = 0.5, pre_trained_path = pre_trained_path):
super().__init__()
self.features = self.make_layers(cfg, batch_norm)
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
self.classifier = nn.Sequential(nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(),
nn.Dropout(drop_p),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(drop_p),
nn.Linear(4096, num_classes))
if init_weights:
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.normal_(m.weight, 0, 1e-4)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
if isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 1e-4)
nn.init.constant_(m.bias, 0)
else:
pass
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def make_layers(self, cfg, batch_norm):
layers = []
in_channels = 3
for v in cfg:
if type(v) == int:
if batch_norm:
layers += [nn.Conv2d(in_channels, v, 3, stride = 1, padding = 1),
nn.BatchNorm2d(v),
nn.ReLU()]
else:
layers += [nn.Conv2d(in_channels, v, 3, stride = 1, padding = 1),
nn.ReLU()]
in_channels = v
else:
layers += [nn.MaxPool2d(2)]
return nn.Sequential(*layers)
- 다음과 같이 딕셔너리 형태로 configurations을 저장하고 make_layers 메서드를 이용하여 cfg에 원하는 구성 값을 입력해주면 자동으로 해당 구성에 맞게 모델이 만들어지도록 코드를 구현하였다.
- A-LRN과 C 같은 경우는 구현하지 않았다.
Training
- 손실함수는 CrossEntropy를 사용.
- 최적화 기법은 Mini-Batch SGD를 사용.
- Momentum = 0.9
- L2 Regularization = 5e-4
- FC Layer에서는 Dropout 기법 사용.
- Drop_p = 0.5
- LR 스케줄링은 validation loss가 더이상 줄어들지 않을 때 LR을 10으로 나누며 진행.
- 가중치 초기화는 $N(0, 0.01)$에서 랜덤하게 뽑아 진행.
- 편향값은 0으로 초기화.
- 빠른 학습과 local minimum에 빠지는 것을 방지하기 위해 pre-initalization 기법도 제안.
- A 모델에서 학습 된 파라미터로 초기화 하는 방법을 제시하였지만 구현은 하지 않았음.
- 논문에서 말하길 학습 속도와 성능 개선이 확실히 있다고 함.
def Train(model, train_DL, val_DL, criterion, optimizer,
EPOCH, BATCH_SIZE, TRAIN_RATIO,
save_model_path, save_history_path, **kwargs):
if "LR_STEP" in kwargs:
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min')
else:
scheduler = None
loss_history = {'train':[], 'val':[]}
acc_history = {'train':[], 'val':[]}
best_loss = 9999
for ep in range(EPOCH):
epoch_start = time.time()
current_lr = optimizer.param_groups[0]['lr']
print(f'Epoch: {ep+1}, current_LR = {current_lr}')
model.train()
train_loss, train_acc, _ = loss_epoch(model, train_DL, criterion, optimizer)
loss_history['train'] += [train_loss]
acc_history['train'] += [train_acc]
model.eval()
with torch.no_grad():
val_loss, val_acc, rcorrect = loss_epoch(model, val_DL, criterion, optimizer)
loss_history['val'] += [val_loss]
acc_history['val'] += [val_acc]
if val_loss < best_loss: #early_stopping
best_loss = val_loss
#optimizer도 같이 save하면 여기서 부터 재학습 가능
torch.save({'model': model,
'ep' : ep,
'optimizier' : optimizer,
'scheduler' : scheduler}, save_model_path)
if 'LR_STEP' in kwargs:
scheduler.step(val_loss)
#print loss
print(f'train loss: {round(train_loss, 5)}, '
f'val loss: {round(val_loss, 5)} \n'
f'train acc: {round(train_acc, 1)} %, '
f'val acc: {round(val_acc, 1)} %, num of valid correct: {rcorrect}, time: {round(time.time()-epoch_start)} s')
print('-'*20)
torch.save({'loss_history': loss_history,
'acc_history' : acc_history,
'EPOCH' : EPOCH,
'BATCH_SIZE' : BATCH_SIZE,
'TRAIN_RATIO' : TRAIN_RATIO}, save_history_path)
return loss_history, acc_history
def loss_epoch(model, DL, criterion, optimizer = None):
N = len(DL.dataset) # number of data
rloss = 0; rcorrect = 0
for x_batch, y_batch in tqdm(DL, leave = False):
#GPU 사용
x_batch = x_batch.to(DEVICE)
y_batch = y_batch.to(DEVICE)
#inference
y_hat = model(x_batch)
#loss
loss = criterion(y_hat, y_batch)
loss.requires_grad_(True)
#update
if optimizer is not None:
optimizer.zero_grad()
loss.backward()
optimizer.step()
#loss accumulation
#shape[0]을 하는 이유는 마지막 배치가 사이즈가 다를수도 있기 때문.
loss_b = loss.item() * x_batch.shape[0] # batch loss
rloss += loss_b
#accuracy accumulation
pred = y_hat.argmax(dim = 1)
corrects_b = torch.sum(pred == y_batch).item()
rcorrect += corrects_b
loss_e = rloss / N #epoch loss
accuracy_e = rcorrect/N * 100
Data Augmentation
- VGGNet의 입력 이미지 사이즈는 224x224이지만 먼저 S라는 크기로 Resize 진행.
- S는 224보다 큰 정수를 일컫음.
- 이후 224 사이즈로 FiveCrop을 진행.
- FiveCrop이란 왼쪽 위, 오른쪽 위, 중앙, 왼쪽 아래, 오른쪽 아래를 기준으로 Crop하는 것.
- 논문에선 Crop 이후 flip도 하며 데이터를 더 늘렸지만 코드 구현에서는 FiveCrop까지만 진행하고 RGB 값의 평균과 분산을 구해 Normalization도 진행을 해주었다.
# To normalize the dataset, calculate the mean and std
train_meanRGB = [np.mean(x.numpy(), axis=(1,2)) for x, _ in train_DS]
train_stdRGB = [np.std(x.numpy(), axis=(1,2)) for x, _ in train_DS]
train_meanR = np.mean([m[0] for m in train_meanRGB])
train_meanG = np.mean([m[1] for m in train_meanRGB])
train_meanB = np.mean([m[2] for m in train_meanRGB])
train_stdR = np.mean([s[0] for s in train_stdRGB])
train_stdG = np.mean([s[1] for s in train_stdRGB])
train_stdB = np.mean([s[2] for s in train_stdRGB])
val_meanRGB = [np.mean(x.numpy(), axis=(1,2)) for x, _ in val_DS]
val_stdRGB = [np.std(x.numpy(), axis=(1,2)) for x, _ in val_DS]
val_meanR = np.mean([m[0] for m in val_meanRGB])
val_meanG = np.mean([m[1] for m in val_meanRGB])
val_meanB = np.mean([m[2] for m in val_meanRGB])
val_stdR = np.mean([s[0] for s in val_stdRGB])
val_stdG = np.mean([s[1] for s in val_stdRGB])
val_stdB = np.mean([s[2] for s in val_stdRGB])
print(train_meanR, train_meanG, train_meanB)
print(val_meanR, val_meanG, val_meanB)
train_transformer = transforms.Compose([
transforms.Resize(256),
transforms.FiveCrop(224),
transforms.Lambda(lambda crops: torch.stack([transforms.ToTensor()(crop) for crop in crops])),
transforms.Normalize([train_meanR, train_meanG, train_meanB], [train_stdR, train_stdG, train_stdB]),
])
test_transformer = transforms.Compose([
transforms.ToTensor(),
transforms.Resize(224),
transforms.Normalize([train_meanR, train_meanG, train_meanB], [train_stdR, train_stdG, train_stdB]),
])
# apply transformation
train_DS.transform = train_transformer
val_DS.transform = test_transformer
test_DS.transform = test_transformer
- 즉, 데이터셋의 크기는 5배 증가하였다.
최종 코드 구현
- 첨부 파일 참고.