ResNeXt
ResNeXt (2017.4)
등장 배경
- CNN 구조가 점점 발전되며 성능을 높일수 있는 여러 방법들이 나왔다.
- 깊이에 중점을 뒀던 VGGNet, Split-Transform-Merge 방법을 제시했던 Inception, Skip-Connection과 Bottleneck 구조로 효율과 새로운 접근 방법을 내놓은 ResNet, 그리고 깊이가 아니라 width가 성능을 올리는 factor라는 것을 밝혀낸 WRN까지 여러 방안들이 나왔다.
- 이와 같이 데이터 공정보다는 네트워크 구조로 성능을 끌어올리려는 시도들이 많이 나왔고 해당 논문 저자들도 새로운 factor를 찾다가 cardinality라는 새로운 요소를 제안한다.
- Cardinality는 Grouped Conv. 에서 그룹의 갯수를 칭하며 실험을 통해 Cardinality가 커질수록 성능이 향상된다는 것을 밝혀냈다.
논문 출처
Grouped Convolution
- ResNeXt 논문에서 가장 메인이 되는 요소는 Grouped Convolution이다.
- 본래 Convolution은 입력 값의 모든 채널을 사용해서 Convolution을 진행하지만 Grouped Convolution은 채널을 구분화하여 따로 Convolution을 진행한다.
- 이후 Conv.의 출력 값을 depth-wise concatenate 한다.
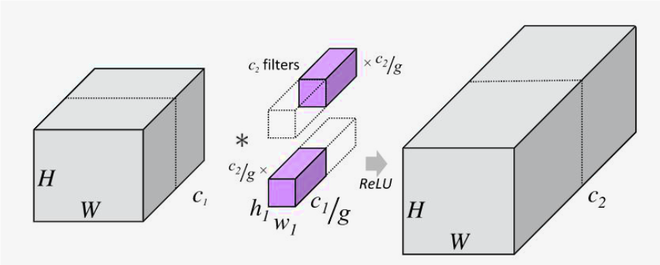
- 위의 그림을 2개의 그룹으로 나누어 Grouped Conv.를 한 예시이다.
- 그러면 왜 Grouped Conv.가 파라미터 갯수가 더 적어지는지 수식으로 알아보자.
- $\text{k = kernel size} \\text{c = input channel} \\text{m = output channel} \\text{g = number of groups}$
- 기존 Convolution이라면 필요한 파라미터 갯수는 $k^2cm$이 될것이다.
- 만약 Grouped Convolution이라면 input channel도 output channel도 그룹의 수 만큼 줄어들 것이다. 즉, $k^2(c/g)(m/g)$는 한 그룹의 파라미터 갯수고 $g$개의 그룹이 존재하니 총 파라미터 갯수는 $(k^2cm)/g$가 된다.
- 그러면 Grouped Convolution의 성능은 어떨까?
- 당연히 기존 Convolution보다 성능이 나쁘게 나온다.
- 물론 파라미터 수가 적은 것도 있겠지만 본래 Convolution 보다 적은 양의 정보 (혹은 채널)을 가지고 연산을 진행하기에 기존 Convolution보다 성능이 나쁘다.
왜 Grouped Convolution을 사용했을까?
- Grouped Convolution이라는 개념이 ResNeXt 논문에서 처음 나온 개념은 아니다.
- CNN의 시초라고 불릴수 있는 AlexNet에서도 사용한 적이 있다. 물론 이때는 성능 개선의 이유보단 2개의 GPU를 효율적으로 사용하기 위해 2개의 그룹으로 나누어 진행하였다.
- AlexNet 이후로 성능만 나빠지는 Grouped Convolution을 사용하는 사람들은 없었다. 하지만 ResNeXt 저자들은 다르게 생각했다. Grouped Convolution으로 아낀 파라미터를 다른 곳에 투자하면 어떨까?
절약한 파라미터를 Bottleneck 구조 완화에 투자하자.
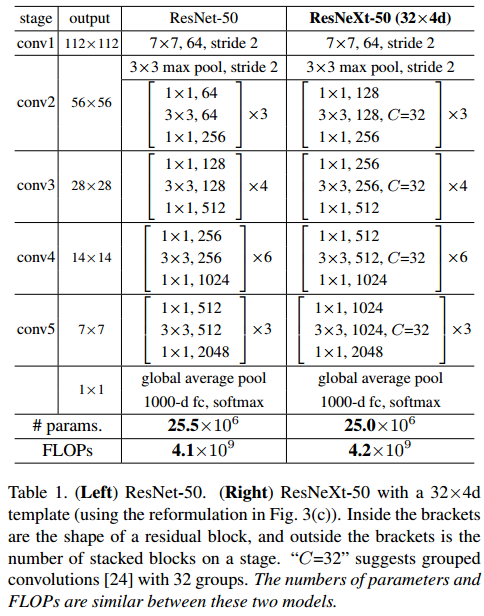
- 좌측 테이블을 보면 기존 ResNet과 ResNeXt를 비교한 테이블이 보인다.
- ResNeXt는 Grouped Convolution을 사용하는데 파라미터 갯수가 기존 ResNet과 큰 차이가 없다. 왜일까?
- 해당 이유는 채널 수를 보면 알 수 있다.
- 기존 ResNet에서는 Bottleneck 구조를 4배수로 사용하였다. 두번째 블록을 보면 256개의 채널을 128개의 채널로 줄이고 3x3 연산을 진행 후 512개의 채널로 증가시킨 반면 ResNeXt는 2배수의 Bottleneck 구조를 사용하였다. 256개의 채널로 줄이고 512개의 채널로 늘렸다.
- ResNet에서 소개된 Bottleneck 구조는 절대 성능 개선을 위해 도입된 것이 아니라 효율을 위해 도입이 되었기에 이에 의한 정보 손실이 막대했을 것이다. 하지만 ResNeXt는 이를 완화시켜 성능을 개선시켰다.
Cardinality의 영향
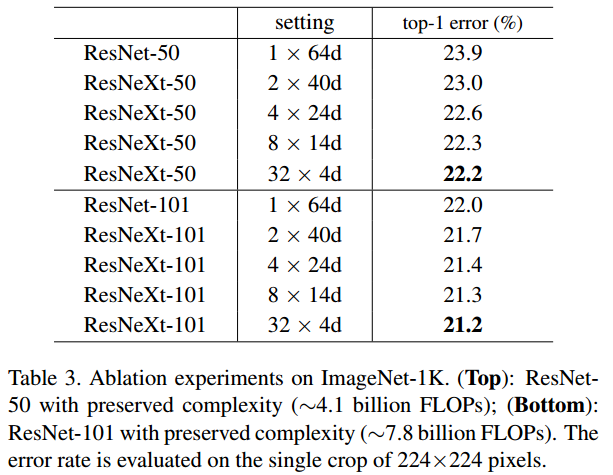
- Cardinality란 위에서 언급한 Grouped Convolution에서 사용되는 그룹의 갯수를 뜻한다.
- 위의 테이블은 Cardinality가 모델 성능에 미치는 영향을 수치화 해본 것이다.
- Setting에 적힌 수치들은 (Cardinality) x (# of channels)의 의미를 가지고 있고 Cardinality가 늘어날수록 성능이 개선되는 것을 볼 수 있다.
Cardinality vs. Width vs. Depth
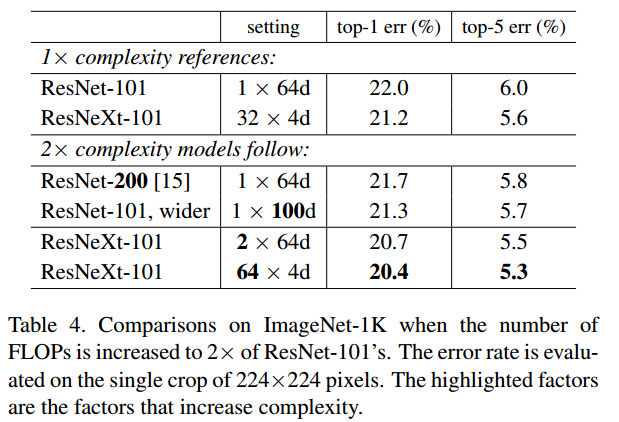
- Depth 2배 증가
- ResNet-101과 ResNet-200을 비교해보면 top-1 error 기준으로 0.3%의 개선이 있었다.
- Width 2배 증가
- ResNet-101과 ResNet-101 wider을 비교해보면 top-1 error 기준으로 0.7%의 개선이 있었다.
- Cardinality 2배 증가
- ResNet-101 1x64d와 ResNeXt-101 2x64d를 비교해보면 top-1 error 기준으로 1.3%의 개선이 있었다.
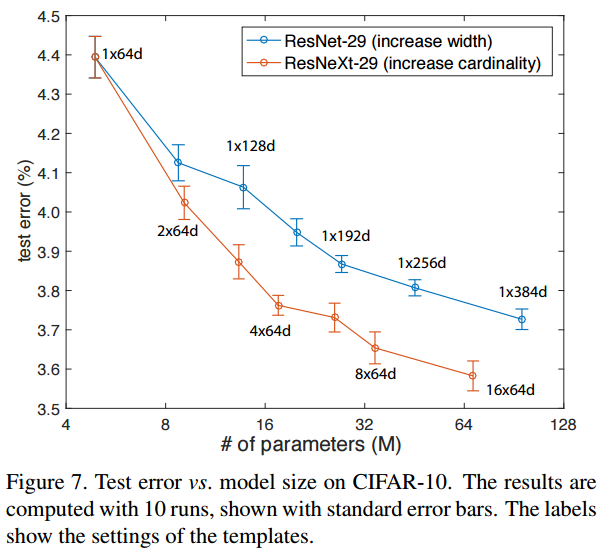
- 해당 그래프는 Cardinality의 성능 개선 능력을 시각화하여 더욱 차이를 느낄수 있게 해준다.
코드 구현
class Bottleneck(nn.Module):
expansion = 2 # 클래스 속성
def __init__(self, in_channels, inner_channels, cardinality, stride = 1, projection = None):
super().__init__()
self.residual = nn.Sequential(nn.Conv2d(in_channels, inner_channels, 1, bias=False),
nn.BatchNorm2d(inner_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inner_channels, inner_channels, 3, stride=stride, padding=1, groups = cardinality, bias=False),
nn.BatchNorm2d(inner_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inner_channels, inner_channels * self.expansion, 1, bias=False),
nn.BatchNorm2d(inner_channels * self.expansion))
self.projection = projection
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
residual = self.residual(x)
if self.projection is not None:
shortcut = self.projection(x)
else:
shortcut = x
out = self.relu(residual + shortcut)
return out
- ResNeXt는 파이토치에서 Conv2d 안에 Grouped Convolution이 내장 되어 있기 때문에 구현이 매우 간단하다.
- 일단 ResNet과 차이가 있는 Bottleneck 클래스의 코드만 가져와봤다.
- 먼저 Bottleneck의 배수를 2로 조정을 해주었다.
- expansion = 2
-
이후 nn.Conv2d에 groups라는 파라미터를 추가해주면 자동으로 Grouped Convolution이 진행된다.
nn.Conv2d(inner_channels, inner_channels, 3, stride=stride, padding=1, groups = cardinality, bias=False),