R-CNN
R-CNN (2013.11)
등장 배경
- 2010년대 초반에는 Object Detection을 위해 그라디언트 기반 모델들이 많이 사용되었다.
- 특히 SIFT나 HOG 알고리즘을 사용한 모델들이 가장 좋은 성능을 내고 있었다.
- 하지만 2012년에 들어서자 성능 개선의 속도가 줄어들기 시작했고 새로운 접근이 필요한 시기가 도래했다.
- 해당 논문의 저자는 최초로 Object Detection 모델에 딥러닝을 적용하기 시작하였고 2-Stage Detector 라는 개념을 도입하였다.
- 2-Stage Detector란 Classification과 Localization을 두 단계로 나누어 진행한다는 것이다.
- 그에 대한 결과로 30 언저리에서 머물던 mAP의 값이 50 이상으로 뛰면서 엄청난 발전을 이루어냈다.
논문 출처
R-CNN의 전반적인 과정
- Selective Search 알고리즘을 이용하여 2000개의 region proposals들을 생성한다. 이후 227x227의 크기로 warp (찌그러트린다는 뜻) 시켜준다.
- 준비된 2000개의 227x227 데이터는 fine-tuned 된 AlexNet에 통과시켜 2000x4096의 feature vector를 생성한다.
- 추출된 vector는 Linear SVM와 Bounding Box Regressor에 통과되어 각각 Confidence Score와 Bounding Box의 좌표를 얻는다.
- NMS를 통해 최소한의 그리고 최적의 Bounding Box들을 추출한다.
이제 위에 설명한 과정 순서대로 세세하게 논문에서 R-CNN을 어떻게 만들었는지 한번 다뤄보도록 하겠다.
Selective Search Region Proposal
Region Proposal 같은 경우 이론 노트에도 적어놨지만 객체가 있을 법한 후보들을 미리 지정해두고 Object Detection을 진행하는 방식이다. 이전에 사용되던 Sliding Window 기법과 달리 조금 더 효율있게 진행할 수 있는 장점이 있다.
Region을 정하기 위해 Selective Search 알고리즘을 택했고 이는 유사도가 가장 높은 영역을 합치는 알고리즘이다.
R-CNN에서는 Selective Search로 2000개의 Region을 추출한 다음에 227x227 사이즈로 warp 해준다.
R-CNN은 AlexNet을 transfer learning 하여 사용하기 때문에 이에 맞게 227x227로 warp 해주지 않으면 모델 사용이 불가하다.
Fine-Tuning AlexNet
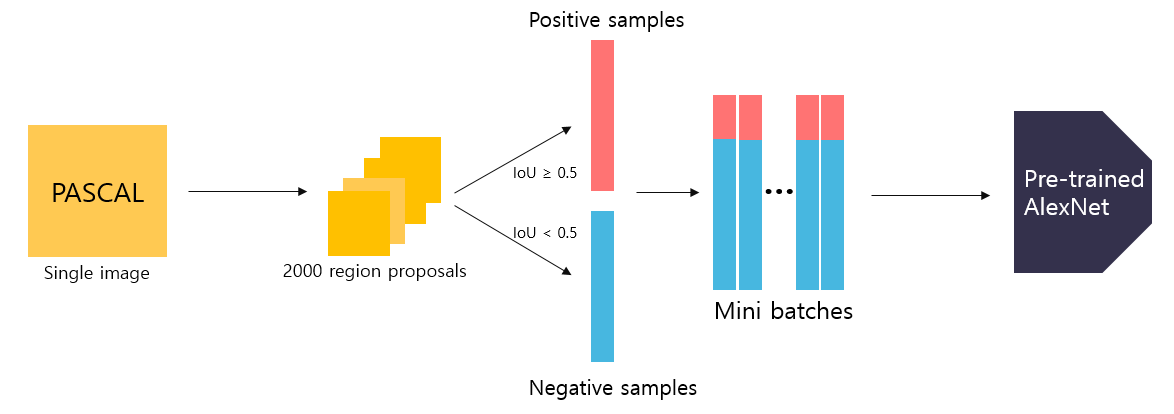
위에서 과정을 설명할 때 warp된 이미지를 가지고 Fine-Tuned AlexNet에 통과시켜 feature를 추출한다고 설명하였다.
이러한 AlexNet을 fine-tuning 하기 위해 논문에선 다음과 같은 방법을 사용하였다.
먼저 PASCAL VOC 데이터셋을 활용하여 학습을 진행한다.
Selective Search를 통해 region proposal을 진행하여 후보 영역들을 추출한다.
추출된 영역들은 객체를 포함할수도 있고 배경을 포함할수도 있기 때문에 Ground Truth와 비교하여 IoU가 0.5이상인 경우는 Positive (객체) 그리고 0.5 이하인 경우는 Negative (배경) 이라고 구분한다.
그리고는 Positive 32개, Negative 96개로 총 128개의 데이터가 담긴 미니 배치를 활용하여 학습을 진행한다.
최종 출력은 2000x4096의 feature vector가 나오게 된다.
Linear SVM Classifier
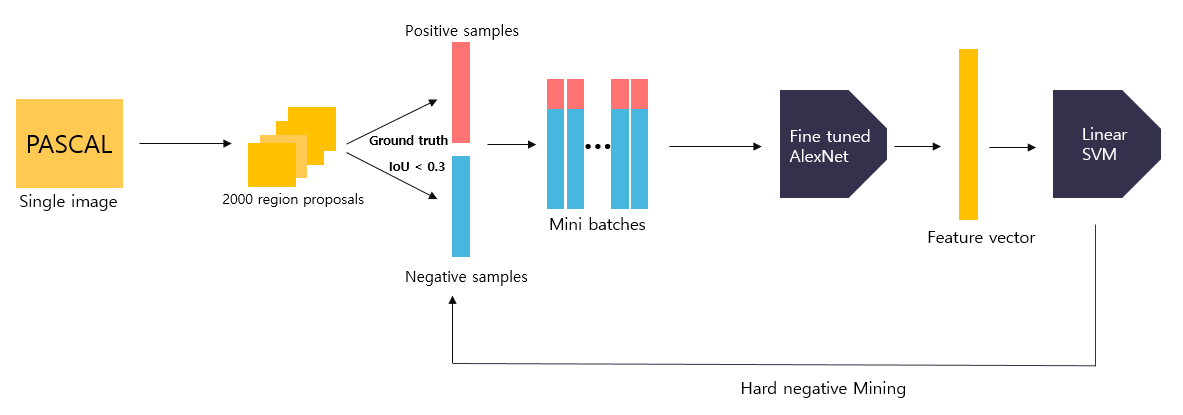
Fine-Tuned AlexNet을 통과하여 나온 feature vector는 최종적으로 linear SVM을 거쳐 confidence score가 나오게 된다.
참고로 SVM은 이진 분류기라 클래스의 수만큼 따로따로 SVM을 학습시켜주어야 한다. 예를 들어 구별해야될 객체가 N개 라면 배경까지 포함하여 N+1개의 SVM을 학습시켜야한다.
SVM을 학습시키는 방법은 위에서 AlexNet을 fine tuning 했을 때와 과정은 동일하다. 하지만 Positive와 Negative의 기준이 달라진다.
Positive는 Ground Truth로만 설정하고 Negative는 Ground Truth와의 IoU가 0.3 미만인 경우로만 택했다. 그리고 1 미만 0.3 이상인 BBox는 무시한다.
왜 fine-tuning때와 기준이 다른가? 에 대한 답변은 다음과 같다.
AlexNet을 튜닝할 때에는 overfitting을 방지하기 위해 조금 더 방대한 양의 데이터이 필요하다고 하기에 기준을 완화시켜 Positive와 Negative의 데이터 수를 늘린 것이다.