MobileNet V1
MobileNet V1 (2017.04)
등장 배경
- 네트워크 이름만 봐도 알다싶이 해당 모델은 Mobile 즉, 휴대폰에서도 동작이 될 정도로 가벼운 모델을 만드는게 목표였다.
- MobileNet은 Depth-wise Separable Convolution이라는 연산을 사용하여 파라미터 수를 대폭 줄이는데 성공하고 Spatial 정보와 Channel-wise 정보를 따로 연산 함을 통해 성능 개선을 이루어냈다.
- MobileNet은 성능보단 효율에 중시하여 개발된 모델이기에 ILSVRC 대회에서 수상을 거두진 못하였다.
논문 출처
Depth-wise Separable Convolution
- 해당 논문에서 Depth-wise Separable Convolution이 처음 소개된 것은 아니지만 적극적으로 활용한 것은 처음이다.
- Depth-wise에서는 각 채널 내의 local spatial information을 담당하고 이후 Point-wise Convolution (1x1 Convolution)을 통해 채널 간의 정보를 aggregate한다.
- 기존 Convolution 같은 경우 local spatial information 과 aggregation을 동시에 진행하여 정보가 entangle 되는 반면 해당 과정을 따로 진행하면서 disentangle 해준다.

- 또한, 당연하듯이 각 Convolution 이후에는 BN과 ReLU가 따라붙는다.
(1) Depth-wise Convolution
- Depth-wise Convolution은 ResNeXt에서 활용한 Grouped Convolution의 응용 버전이다.
- Grouped Conv.에서는 Cardinality라는 수치로 그룹을 나누었는데 Depth-wise Convolution은 Cardinality가 in channel 수와 같아 필터 하나당 채널 하나를 맡는다.
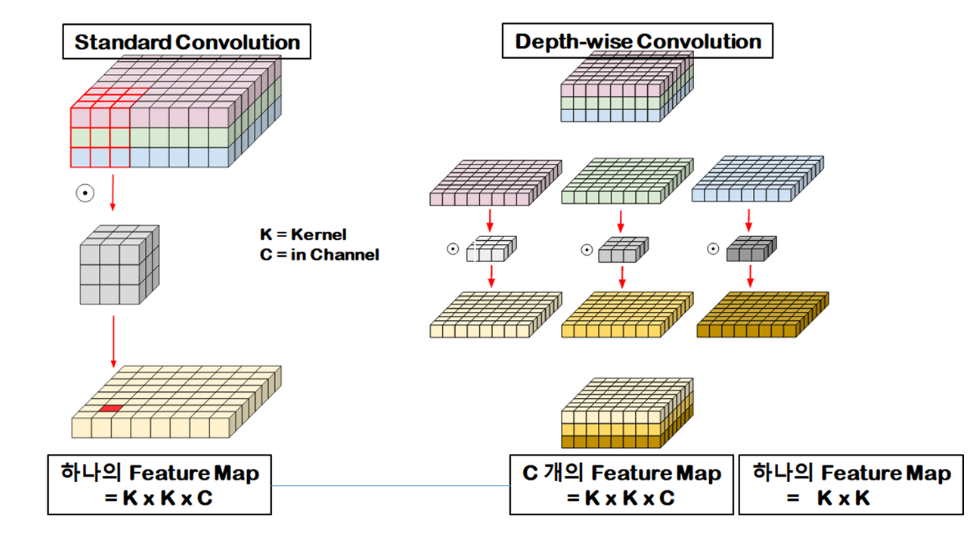
- 이후 각 필터 맵들은 더해지는 것이 아니라 concatenate되게 된다. 즉, in channel 수와 out channel 수는 같다.
(2) Point-wise Convolution

Depth-wise Convolution과 Point-wise Convolution이 합쳐진 Depth-wise Separable Convolution의 완전체이다.
-
Point-wise Convolution은 Bottleneck에서 채널 수를 늘리고 줄이기 위해 사용되던 1x1 Convolution과 같은 의미이다. (1x1 Convolution은 피처 맵간 weighted sum이다.)
-
1x1 Convolution으로 채널 간의 정보를 aggregate 해주고 채널 수를 조정해준다.
Depth-wise Separable Convolution의 효율성
- 기존 Convolution의 연산량은 다음과 같이 표기할 수 있다.
- $D_K \cdot D_K\cdot M\cdot N \cdot D_F \cdot D_F$
- $D_K$는 커널의 사이즈, $M$은 입력 채널 수, $N$은 출력 채널 수, $D_F$는 피처 맵의 사이즈를 말한다.
- Depth-wise Convolution의 연산량은 다음과 같이 표기할 수 있다.
- $D_K \cdot D_K\cdot M\cdot D_F \cdot D_F$
- 출력 채널 수가 1이고 채널 수 만큼 필터가 존재하기에 다음과 같은 연산량이 나온다.
- Point-wise Convolution의 연산량은 다음과 같이 표기할 수 있다.
- $M\cdot N\cdot D_F \cdot D_F$
- 커널 사이즈가 1이기에 피처 맵 사이즈만큼 합성곱이 진행되고 입력 채널 수 만큼의 채널을 가진 필터가 출력 채널 수 만큼 존재하기에 $M \cdot N$만큼 진행된다.
- 기존 Convolution vs. Depth-wise Separable Convolution
- $\dfrac{D_K \cdot D_K\cdot M\cdot N \cdot D_F \cdot D_F}{D_K \cdot D_K\cdot M\cdot D_F \cdot D_F+M\cdot N\cdot D_F \cdot D_F} = \dfrac{1}{N} + \dfrac{1}{D^2_K}$
- 논문 상에서는 약 8~9배의 파라미터 수 차이가 난다고 한다.
전체 구조
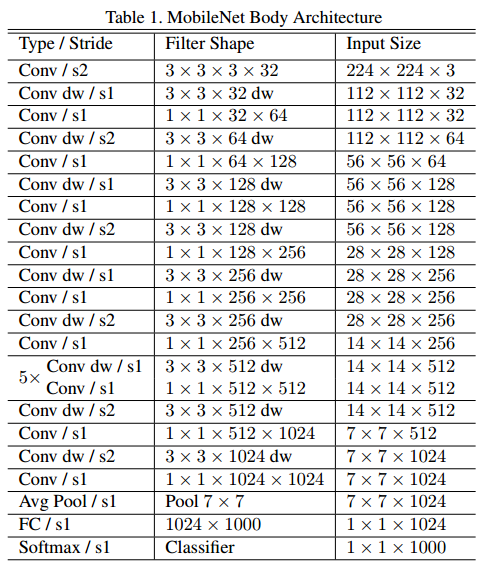
- 첫 Conv를 제외하고는 전부 Depth-wise Separable Convolution으로 진행된다.
- Conv dw는 Depth-wise Convolution을 뜻하고 그 뒤에 따라오는 Conv는 1x1 convolution으로 Point-wise Convolution이 진행된다.
- Downsampling 같은 경우 풀링이 아니라 중간 중간에 stride = 2로 진행하였다.
- 또한 MobileNet은 오래간만의 VGGNet을 backbone으로 사용한 모델이다.
- 여태껏 ResNet 혹은 Inception을 backbone으로 삼아 개발된 모델이 많았다.
성능 검증
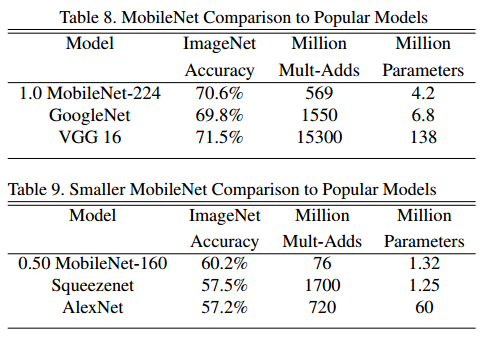
- 표를 보면 MobileNet의 경우 무려 고작 420만의 파라미터를 가지고 VGGNet과 GoogLeNet과 비슷한 성능을 내는 것을 볼 수 있다.
- VGGNet과 비교하면 약 30배의 차이이다.
- 정말 미친 효율을 내는 엄청난 발견이란 것을 알 수 있다.
Latency and Accuracy Trade-Off
- Latency와 Accuracy에 대한 부분을 논문 초록에서부터 상당히 강조를 해왔다.
- 논문의 목적이 모바일 환경 혹은 임베디드 환경에서 사용할 수 있는 모델을 만드는 것이다보니 강조가 상당히 되었다.
- 논문에서는 Latency와 Accuracy를 조정할 수 있는 두개의 하이퍼 파라미터를 소개하였다.
- $\alpha$ width multiplier
- $\rho$ resolution multiplier
(1) Width Multiplier
- 사실 개념 자체는 굉장히 간단하다. $\alpha$를 각 채널 수에 곱해주어 모델의 width를 줄여 accuracy를 소모하고 latency를 줄여준다는 것이다.
- 채널 수가 줄어들면 파라미터 수가 줄어들어 당연히 연산 속도가 빨라져 latency가 줄어들 것이다.
- Width Multiplier를 적용한 연산은 다음과 같이 진행된다.
- $D_K \cdot D_K\cdot \alpha M\cdot D_F \cdot D_F+\alpha M\cdot \alpha N\cdot D_F \cdot D_F$
- Width Multiplier는 보통 1, 0.75, 0.5, 0.25로 설정하는데 그 이유는 채널 수가 대부분 4의 배수로 이루어져 정수로 딱 나눠 떨어지기 때문이다.
- 만약 4의 배수가 아니라면 int() 캐스팅을 사용하여 flooring을 해준다.
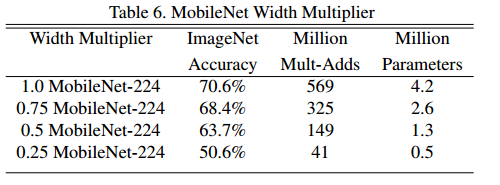
- 채널 수가 줄어듦으로써 성능이 줄어드는 것을 볼 수 있다. $\alpha = 0.25$일시 성능이 확 떨어지는 것을 볼 수 있다. 이 때는 trade-off가 무너진다는 것이다.
(2) Resolution Multiplier
- Resolution Multiplier도 개념은 같다. $\rho$를 피처 맵 사이즈에 곱해주어 모델의 피처 맵 사이즈를 줄여 파라미터 수를 줄인다. 그러면 연산량이 줄어 latency가 줄어들 것이다.
- Resolution Multiplier를 적용한 연산은 다음과 같다.
- $D_K \cdot D_K\cdot M\cdot \rho D_F \cdot \rho D_F+M\cdot N\cdot \rho D_F \cdot \rho D_F$
- $\rho$는 $0 < \rho < 1$의 범위를 가지며 보통 해상도는 224, 192, 160, 128로 조정한다. 그리고 이것도 정수로 안떨어질 시 flooring을 진행한다.
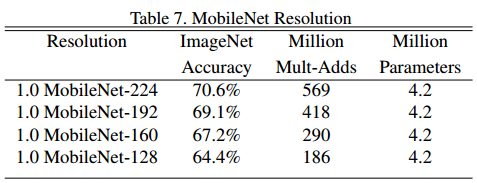
- 여기도 채널 수와 동일하게 해상도가 낮아질수록 성능이 낮아지는 것을 볼 수 있다.
Narrow vs. Shallow
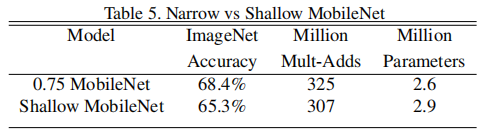
- 논문에서는 추가적인 실험을 진행했는데 width를 줄이는 것과 depth를 줄이는 것 중에 어느 것이 trade-off가 덜 할까를 확인해보는 실험이었다.
- 표에서 보이다싶이 채널을 줄이는 것이 성능이 더 잘 나오는 것을 볼 수 있다.
- 다음과 같은 결과때문에 trade-off를 컨트롤하는 하이퍼 파라미터로 width multiplier를 택한 것을 볼 수 있다.
코드 구현
(1) DepSep Block 클래스
class DepSepConv(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
self.depthwise = nn.Sequential(nn.Conv2d(in_channels,in_channels,3, stride = stride, padding = 1, groups = in_channels, bias=False),
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True))
self.pointwise = nn.Sequential(nn.Conv2d(in_channels,out_channels,1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True))
def forward(self, x):
x = self.depthwise(x)
x = self.pointwise(x)
return x
- Depth-wise Convolution을 구현하기 위해 Conv2d에서 입력 채널 수와 출력 채널 수를 동일하게 해주고 groups 파라미터에도 입력 채널 수로 넣어준다.
- Point-wise Convolution은 기존 1x1 Convolution과 동일하다.
(2) MobileNet 클래스
class MobileNet(nn.Module):
def __init__(self, alpha, num_classes=1000):
super().__init__()
self.conv1 = nn.Conv2d(3, int(32*alpha), 3, stride=2, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(int(32*alpha))
self.relu = nn.ReLU(inplace=True)
self.conv2 = DepSepConv(int(32*alpha), int(64*alpha), stride=1)
self.conv3 = nn.Sequential(DepSepConv(int(64*alpha), int(128*alpha), stride=2), # down sample
DepSepConv(int(128*alpha), int(128*alpha)))
self.conv4 = nn.Sequential(DepSepConv(int(128*alpha), int(256*alpha), stride=2), # down sample
DepSepConv(int(256*alpha), int(256*alpha)))
self.conv5 = nn.Sequential(DepSepConv(int(256*alpha), int(512*alpha), stride=2), # down sample
*[DepSepConv(int(512*alpha), int(512*alpha)) for i in range(5)])
self.conv6 = nn.Sequential(DepSepConv(int(512*alpha), int(1024*alpha), stride=2), # down sample
DepSepConv(int(1024*alpha), int(1024*alpha)))
self.avg_pool = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Linear(int(1024*alpha), num_classes)
# weights initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = self.conv6(x)
x = self.avg_pool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
- 첫번째 Convolution은 Depth-wise Separable Convolution을 하지 않기에 따로 코드를 작성해준다.
- 이후로는 DepSepBlock 클래스를 사용하여 만들어주고 논문의 구조대로 downsampling은 stride를 이용하여 진행해준다.
- Width Multiplier는 MobileNet의 입력 파라미터로 받아 int(in_channels * alpha)로 채널 수를 조정해준다.
- Resolution Multiplier같은 경우 이미지 전처리 과정에서 진행하기에 코드 구현은 따로 진행하지 않았다.