Inception V2/V3
Inception V2/V3 (2015.12)
등장 배경
- VGGNet과 Inception의 등장으로 CNN은 깊어질수록 성능이 극대화된다는 것은 당연시한 사실이 되었다.
- 그렇기에 깊어질수록 기하급수적으로 늘어나는 computational cost를 handle하는 것이 주 목적이되었다.
- 해당 논문에서는 Inception V1에서 효율을 더욱 극대화 하여 모듈을 변경하였다.
- 여러 근거와 Principle을 바탕으로 모듈을 재구성하였고 이를 통해 새로운 Inception V2 모델을 만들었다.
- 이후 몇 가지 세세한 테크닉을 추가하여 V3 모델까지 만들어냈다.
논문 출처
General Design Principle
- Avoid Representational Bottleneck, especially early in the network
- 해당 Principle은 representational bottleneck에 대한 경고를 주었다. Representational bottleneck이란 풀링 혹은 큰 스트라이드의 크기로 인해 피처맵의 사이즈가 대폭 줄어들어 representation에 대한 정보가 손실되는 것을 일컫는다.
- 피처 맵의 사이즈는 네트워크 초반부터 후반까지 조금씩 점진적으로 줄어들어야하는 것이 정상적이며 급격하게 줄어들면 입력값에 대한 representational information이 손실되어 제대로된 이미지 식별을 하지 못하는 것이다.
- 급격하게 채널을 늘리는 것에만 집중하는 것은 좋지 않다. Dimensionality는 rough한 정보만 넘겨줄뿐 correlation같은 중요한 요소들은 포함하지 않기에 풀링을 통해 채널을 늘리는데에만 집중하면 안된다는 뜻이다.
- Higher dimensional representations are easier to process locally within a network
- 즉, 여기서 하고픈 말은 피처 맵의 채널 수가 깊어질수록 네트워크가 훈련하기 더욱 쉬워지고 속도도 더 빨라진다는 것이다.
- 피처 맵의 채널 수가 많아진다 혹은 dimension이 커진다 라는 뜻은 이미지를 나타내는 특성의 수를 더욱 늘릴 수 있다는 뜻이다.
- 예를 들어 채널 1에 있는 맵은 눈, 채널 2는 코, 채널 3은 입. 이런 식으로 말이다.
- 이러면 한 채널에 여러 특징이 있는 tangled 된 상황이 아니라 한 채널의 한가지 특징만 있는 disentangled한 상황이 되는 것이다.
- Spatial aggregation can be done over lower dimensional embeddings without much or any loss in representational power.
- 여기서 말하는 Spatial Aggregation이란 3x3 컨볼루션이나 풀링 같이 특성 맵의 크기를 줄이는 행위들을 말한다.
- 3번에서 강조하는 것은 spatial aggregation은 초반 단계에서 이루어지면 표현력 부분에서 손실이 크지 않다는 것이고 그렇기에 초반에는 spatial aggregation 전에 dimension reduction (e.g. 1x1 convolution)을 하면 표현력 손실 없이 계산적 비용을 줄일 수 있다는 말이다.
- 그 이유는 논문에선 추측하기론 초반 단계에서는 인접한 유닛들이 큰 상호 관계를 가지고 있기에 표현력 손실이 후반에 비해 적기 때문이라고 한다.
- Balance the width and depth of the network.
- CNN에서 성능을 올리려면 width (커널의 채널 수)와 depth (네트워크의 깊이)를 둘 다 늘려야된다.
- 논문에서 말하길 width와 depth는 computational cost를 고려하여 balance하게 증가시켜야된다고 한다.
Factorization into Smaller Filter Size
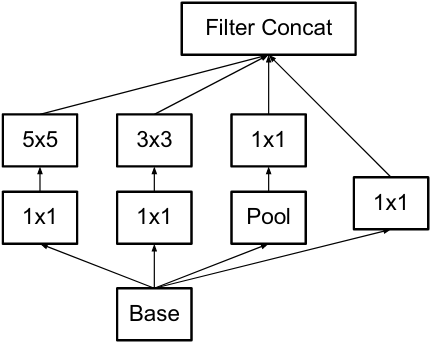
기존 모듈
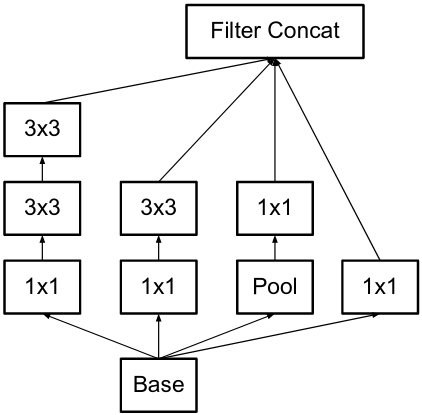
새로운 모듈
- 왼쪽이 기존 모듈이고 오른쪽이 변경된 모듈이다.
- 5x5 필터가 두개의 3x3 필터로 변경된 것을 볼 수 있는데 이는 파라미터 수를 줄이며 표현력의 손실을 방지 할 수 있다.
- 이전 5x5 필터의 입력 사이즈와 출력 사이즈를 동일하게 가져가면 표현력의 손실은 크지 않을 것이다.
- 그리고 위에 언급한 3번 principle에서 볼수 있듯이 1x1필터를 먼저 적용하여 dimension을 줄인 다음 spatial aggregation을 한 것을 볼 수 있다.
Spatial Factorization into Asymmetric Convolution
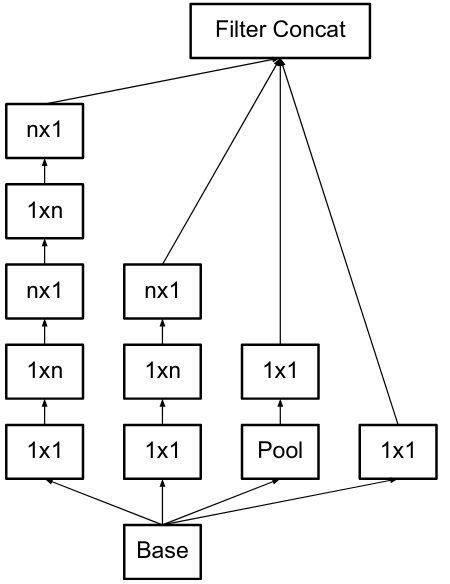
- 위에서 말한 것과 같이 factorization을 하면 파라미터 수를 더 줄일 수 있는데 3x3을 2개의 2x2로 나누면 더 가성비가 좋아지지 않을까?
- 하지만 그것보다 1xn, nx1의 형식으로 나누는 게 더 가성비가 좋다고 한다. 하지만 해당 방식은 초기 단계에서는 큰 효과를 보이지 않고 중간 단계 (피처 맵의 사이즈가 17일때) 적용하면 성능이 좋다고 한다.
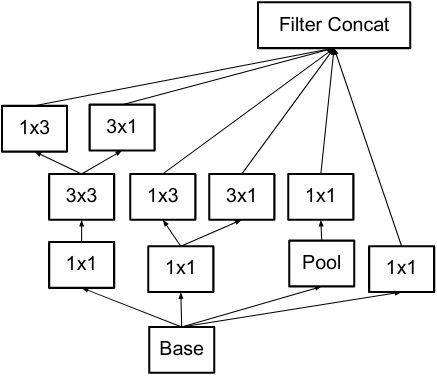
- 그리고 해당 모듈은 모델의 후반부 (피처맵이 8x8일때)에서 사용되었는데 이유는 dimension을 높임으로써 disentangled된 피처를 만들어 특성을 더욱 더 잘 나누기 위함이라고 한다. (2번 principle에 의거)
Utility of Auxiliary Classifier
- Inception V1 모듈에서 부터 거론된 보조 분류기이다. V1에서는 vanishing gradient를 막아주는 역할로 도입되었다고 하였는데 이번 논문에서는 그 의견을 철회하였다.
- 보조 분류기의 역할은 regularizer로 정정하였다. 필자도 해당 의견이 맞다고 생각되는 이유가 중간 단계에서의 분류 값이 최종 값에 더해지면서 최종 값에 대한 확신을 조금은 덜어줄 것이다. 그러면서 regularize의 역할을 해줄 것이다.
- 또한 실험 결과 초반에 있던 보조 분류기는 있나마나 성능의 차이가 없어서 없앴다고 한다. 결국 Inception V3에선 한개의 보조 분류기만을 가지고 있다.
Efficient Grid Size Reduction
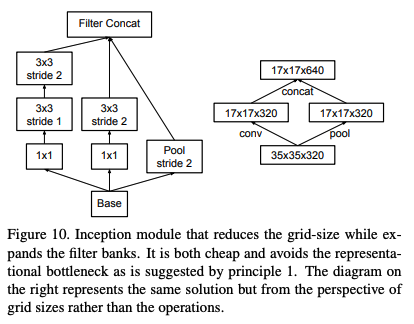
- 위의 1번 principle에서 언급된 사항에 의거 풀링의 방법을 수정하였다.
- 원래 풀링 진행 전 representation 정보 손실을 방지하기 위해 채널 수를 늘려주고 풀링을 진행하였는데 이러면 computational cost가 너무 높다.
- 기존 Inception 모듈에선 inception 통과 후 풀링을 진행하였는데 이러면 representational 병목현상이 발생한다.
- 그렇기에 풀링과 stride가 2인 convolution을 병렬적으로 진행 후 concat를 하는 방식으로 해결하였다.
Label Smoothing
- 본래 정답 라벨은 원-핫 인코딩된 형태로 존재했다.
- 즉, [1,0,0,0] 이런 식으로 정답 벡터가 존재했다면 label smoothing은 해당 벡터를 [0.9, 0.033, 0.033, 0.033] 이런 식으로 오답에도 일정 값을 준다.
- 해당 과정을 통해 정답에 대한 확신을 조금 줄여줌으로써 regularization 효과를 볼 수 있다. (즉, overfitting 방지 효과가 있다).
Inception V3
- 여태껏 설명했던 내용은 V2에 해당되는 내용이고 V2에 조그마한 변형을 준 것이 V3이다.
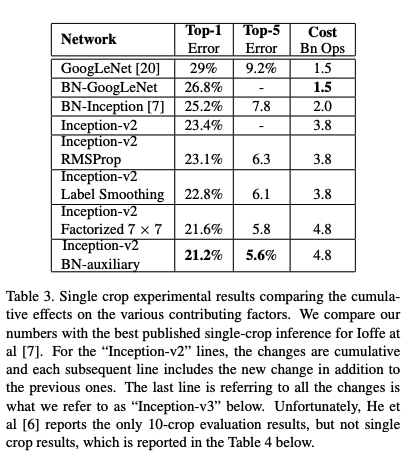
- 맨 마지막에 있는 Inception-v2 BN-auxiliary가 v3인데 위에 있는 것들이 누적되어있는 것이다.
- 즉, RMSProp, Label Smoothing, Factorized 7x7, BN-auxiliary까지 합한 것이 Inception V3이다.