Inception V1
Inception V1 (GoogLeNet)
요약
- Inception V1, 또는 GoogLeNet은 CNN의 깊이를 늘리면서도 계산 비용과 과적합 문제를 해결하기 위해 Inception Module을 도입한 모델이다. 이 모델은 여러 필터를 병렬로 사용하고, 차원 축소를 통해 효율성을 높이며, Auxiliary Classifier를 통해 Vanishing Gradient 문제를 완화한다. 최종적으로 약 1300만 개의 파라미터를 사용하여 VGGNet보다 훨씬 적은 자원으로 높은 성능을 발휘한다.
등장 배경
- Inception V1 혹은 GoogLeNet은 VGGNet과 같은 시기에 나온 모델이다.
- ILSVRC-2014에서 VGGNet을 제치고 1등을 차지한 모델이다.
논문 출처
- C. Szegedy et al. Going deeper with convolutions arXiv:1409.4842, 2014
간단 소개
- CNN의 성능을 높이기 위해선 깊이를 깊게 만드는 것이 불가피한 일이다.
- 하지만 깊게 만들면 생기는 문제가 2가지 있다.
- Computational Cost의 상승
- Overfitting
- 해당 문제를 해결하고자 제안한 것이 Inception Module이다.
- Inception은 Hebbian Principle에서 영감을 받아 만든 모듈이며 해당 모듈을 활용하면 cost를 적게 들이면서도 깊이를 깊게 만들 수 있다.
- 즉, GoogLeNet은 효율중시모델이다.
기존 문제점
- 현재 컴퓨터 인프라는 Sparse Matrix 계산에 매우 비효율적이다.
- 그렇기에 해당 논문 작성자는 sparse한 CNN 모델에서 optimal local sparse structure를 찾고 이를 반복하여 dense하게 작동되도록 하는 것이다.
- 그렇게 하여 탄생한게 Inception Module이다.
Inception Module
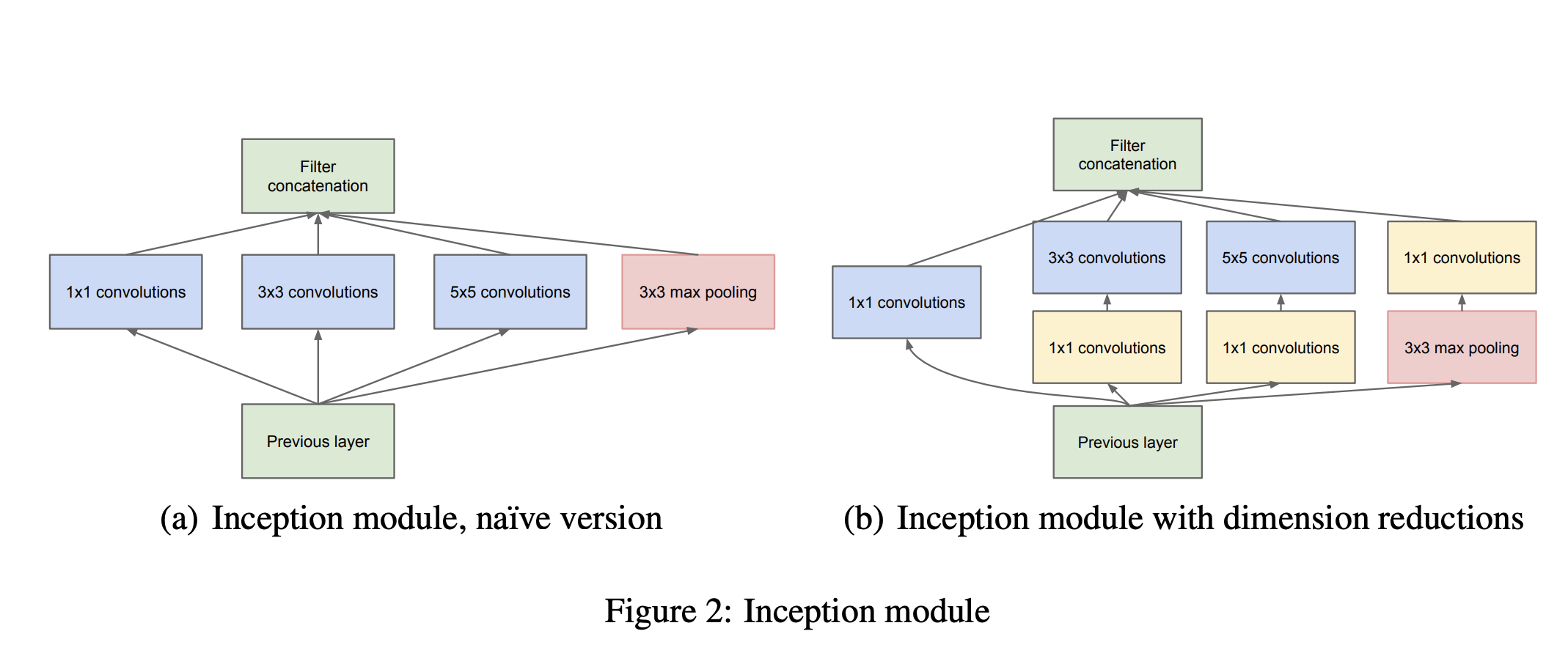
- 왼쪽에 Naive 버전을 먼저 보도록 하자.
- 1x1, 3x3, 5x5 필터가 병렬적으로 계산이 되고 풀링도 시행이 된다.
- 이후 나온 피처맵들을 Depth 방향으로 하나의 피처 맵으로 합친다.
- 하지만 그림으로도 보이다싶이 4개의 병렬 계산이 한번에 이루어지는데 매우 무거워보인다.
- 실제 실험에서도 Cost가 그렇게 많이 줄어들지 않아서 Dimension Reduction 방식을 도입하였다.
- ‘Network in Network’ 논문의 아이디어를 따라 3x3, 5x5 필터 계산 전에 1x1 Conv. 를 통과시켜 차원을 줄이고 풀링 이후 1x1 Conv.를 한번 더 시행하여 차원을 줄였다.
Dimension Reduction
- 1x1 컨볼루션을 통과시키는게 차원이 줄어드나? 싶은 의문이 들 수도 있다.
- 만약 in_channels = 192, out_channels = 128인 3x3 Conv. 레이어가 있다고 하자. 이때 필요한 파라미터 갯수는 128x192x3x3 = 221,184개의 파리미터가 필요하다.
- 하지만 1x1을 먼저 통과시킨다면? (192 ⇒ 96 ⇒ 128) 96x192x1x1 + 128x96x3x3 = 129,024
- 거의 반절에 가까운 양의 파라미터가 줄어든다.
GoogLeNet
- Inception Module을 여러 번 반복하여 최종적으로 만들어진 네트워크는 GoogLeNet이라고 이름을 붙였다.
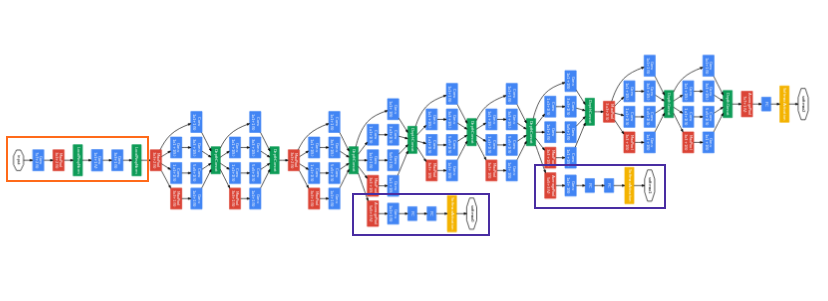
세로로 너무 길어서 가로로 이미지를 삽입하였다 ㅋ…
- 가장 아래의 주황색 박스를 보자.
- 논문에 나오길 처음부터 Inception Module을 도입하면 성능이 그렇게 좋게 안나온다고 하였다.
- 그래서 초반에는 일반적인 Conv, Pooling, BN으로 반복되는 아키텍쳐가 도입되었다.
- GoogLeNet의 가장 큰 특징인 파란색 박스를 보자.
- Auxiliary Classifier라고 불리우는 부분이다.
- 해당 부분은 네트워크 중간에 FC Layer를 통과시켜 결과값을 도출해낸다.
- 총 2번 중간에 출력 값을 내보내고 이때 나온 loss값은 weight 0.3을 곱하여 최종 loss에 더해진다.
- 해당 부분이 더해지면서 Vanishing Gradient의 고질적인 문제를 어느정도 해결했다고 볼 수 있다.
Global Average Pooling (GAP)
- 위의 GoogLeNet 그림을 보면 마지막에 7x7 사이즈의 Average Pooling을 통과한다.
- ImageNet 기준 입력 이미지가 224x224라고 했을 때 최종 피처 맵 사이즈는 7x7이므로 이는 GAP를 의미한다.
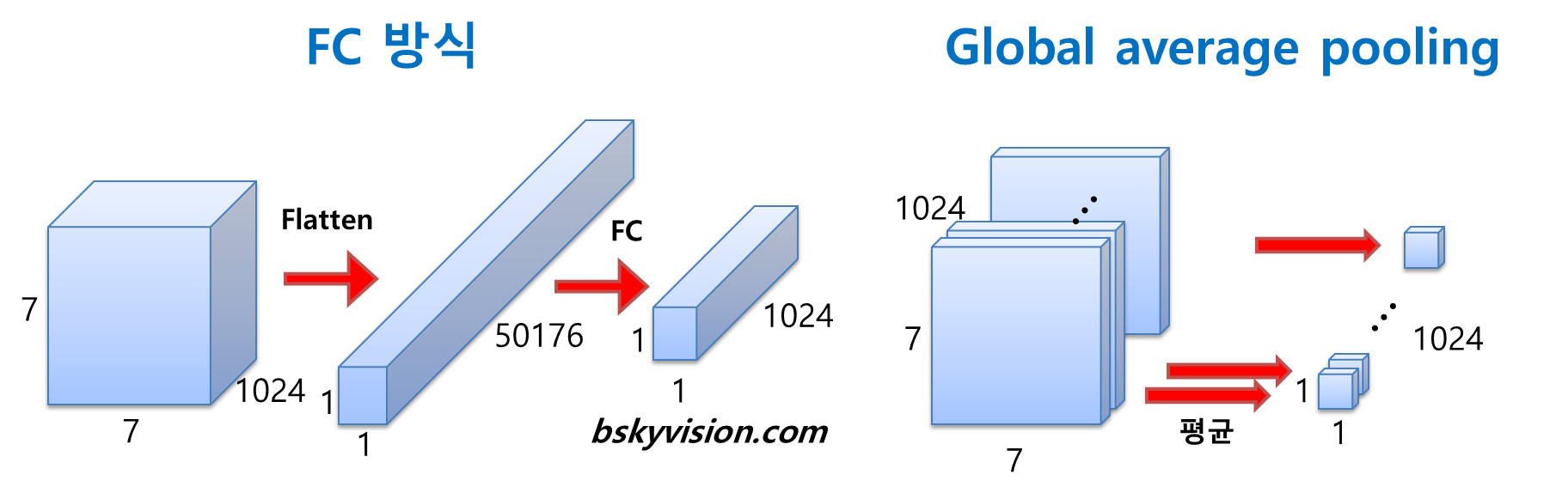
- 왜 flatten 하여 fc를 통과하지 않고 GAP를 도입했을까?
- flatten을 하면 피처맵의 위치적 특성이 사라져버린다.
- 하지만 GAP를 하면 위치적 특성을 그대로 들고 최종 FC Layer를 통과할 수 있다.
- 그리고 Dense한 FC Layer 두개를 통과하는 것보다 파라미터 갯수가 훨씬 줄어든다.
코드 구현
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super().__init__()
self.conv_block = nn.Sequential(nn.Conv2d(in_channels, out_channels, bias=False, **kwargs),
nn.BatchNorm2d(out_channels, eps=0.001),
nn.ReLU())
def forward(self, x):
x = self.conv_block(x)
return x
class Inception(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):
super().__init__()
self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
self.branch2 = nn.Sequential(BasicConv2d(in_channels, ch3x3red, kernel_size=1),
BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1)) # red는 reduce를 줄인 것
self.branch3 = nn.Sequential(BasicConv2d(in_channels, ch5x5red, kernel_size=1),
BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2))
# Here, kernel_size=3 instead of kernel_size=5 is a known bug. (버그 fix: kernel_size 3=>5, padding 1=>2 로 변경)
# Please see https://github.com/pytorch/vision/issues/906 for details.
self.branch4 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, pool_proj, kernel_size=1))
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs,1)
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes, drop_p = 0.7):
super().__init__()
self.avgpool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = BasicConv2d(in_channels, 128, kernel_size=1)
self.fc1 = nn.Linear(2048, 1024)
self.act = nn.ReLU()
self.dropout = nn.Dropout(p=drop_p)
self.fc2 = nn.Linear(1024, num_classes)
def forward(self, x):
# aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14
x = self.avgpool(x)
# aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4
x = self.conv(x)
# N x 128 x 4 x 4
x = torch.flatten(x, 1)
# N x 2048
x = self.fc1(x)
x = self.act(x)
x = self.dropout(x)
# N x 1024
x = self.fc2(x)
# N x 1000 (num_classes)
return x
class Inception_V1(nn.Module):
def __init__(self, num_classes = 1000, use_aux = True, init_weights = None, drop_p = 0.4, drop_p_aux = 0.7):
super().__init__()
self.use_aux = use_aux
self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(3, stride=2, padding=1)
self.conv2a = BasicConv2d(64, 64, kernel_size=1)
self.conv2b = BasicConv2d(64, 192, kernel_size=3, padding=1)
self.maxpool2 = nn.MaxPool2d(3, stride=2, padding=1)
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(3, stride=2, padding=1)
self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(3, stride=2, padding=1)
self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)
if use_aux:
self.aux1 = InceptionAux(512, num_classes, drop_p=drop_p_aux)
self.aux2 = InceptionAux(528, num_classes, drop_p=drop_p_aux)
else:
self.aux1 = None
self.aux2 = None
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # GAP
self.dropout = nn.Dropout(p=drop_p)
self.fc = nn.Linear(1024, num_classes)
if init_weights:
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.Linear):
torch.nn.init.trunc_normal_(m.weight, mean=0.0, std=0.01, a=-2, b=2)
def forward(self, x):
# N x 3 x 224 x 224
x = self.conv1(x)
# N x 64 x 112 x 112
x = self.maxpool1(x)
# N x 64 x 56 x 56
x = self.conv2a(x)
# N x 64 x 56 x 56
x = self.conv2b(x)
# N x 192 x 56 x 56
x = self.maxpool2(x)
# N x 192 x 28 x 28
x = self.inception3a(x)
# N x 256 x 28 x 28
x = self.inception3b(x)
# N x 480 x 28 x 28
x = self.maxpool3(x)
# N x 480 x 14 x 14
x = self.inception4a(x)
# N x 512 x 14 x 14
if self.aux1 is not None and self.training:
aux1 = self.aux1(x)
else:
aux1 = None # 뭐라도 넣어놔야 not defined error 안 뜸
x = self.inception4b(x)
# N x 512 x 14 x 14
x = self.inception4c(x)
# N x 512 x 14 x 14
x = self.inception4d(x)
# N x 528 x 14 x 14
if self.aux2 is not None and self.training:
aux2 = self.aux2(x)
else:
aux2 = None
x = self.inception4e(x)
# N x 832 x 14 x 14
x = self.maxpool4(x)
# N x 832 x 7 x 7
x = self.inception5a(x)
# N x 832 x 7 x 7
x = self.inception5b(x)
# N x 1024 x 7 x 7
x = self.avgpool(x)
# N x 1024 x 1 x 1
x = torch.flatten(x, 1)
# N x 1024
x = self.dropout(x)
x = self.fc(x)
# N x 1000 (num_classes)
return x, aux2, aux1
- 구현 자체는 그렇게 어렵지 않았다.
- Inception Module과 Aux. Classifier는 클래스화하여 최종 Inception V1 클래스에 넣어주고 리턴 값에 각각 aux를 통과하여 나온 확률 값과 최종 확률 값 총 3개를 리턴 시켜주면 된다.
===============================================================================================
Total params: 13,385,816
Trainable params: 13,385,816
Non-trainable params: 0
Total mult-adds (G): 3.17
===============================================================================================
Input size (MB): 1.20
Forward/backward pass size (MB): 103.25
Params size (MB): 28.02
Estimated Total Size (MB): 132.48
===============================================================================================
- 사용되는 파라미터 갯수도 약 1300만개로, VGGNet에 비해 10배 정도 적다.
- VGG-19는 약 1억3천만개정도…