GPT-1
GPT (Generative Pre-Trained) - 1
논문 출처
https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
논문 소개
- GPT-1은 OpenAI사에서 2018년 6월에 공개한 모델로써 현재 많이들 쓰이는 ChatGPT의 근간이 되는 모델이다.
- GPT-1은 기존 자연어 처리 작업에서 있었던 여러 문제들을 해결하기 위한 목적을 가지고 있으며 궁극적으로 자연어 처리의 모든 분야에 사용될 수 있는 Pre-Trained 모델을 만들려 시도한 모델읻.
기존 방법의 문제점
데이터 부족
- 논문에서 제시한 기존의 문제점은 라벨링된 데이터의 부족이다. 기존 딥러닝 모델들은 지나치게 지도 학습 방식에 의존을 하지만 라벨링된 데이터의 수는 매우 부족하다.
- 이 때문에 기술의 발전이 늦어지고 있다는 것이 논문에서 제시한 문제점이다.
- 그렇기 때문에 raw data를 이용한 비지도 학습을 사용하여 더 많은 양의 데이터를 모델 학습에 사용하게 해야된다는 것이 논문의 주요 논점이다.
- 또한, 비지도 학습을 통해 기본적은 representation을 학습하고 이후 지도 학습을 통한 fine-tuning을 하는 것이 성능 개선에도 큰 효과를 보인다고 말한다.
전이 학습의 전례 부족
- 자연어 처리 부분에서의 전이 학습은 기존에 흔한 방법은 아니었다.
- 그렇기에 전이 학습을 위한 pre-trained 모델을 학습하기 위한 목표 함수는 뭘까? 라는 질문과 전이를 가장 효과적이게 할 수 있는 방법은 뭘까? 라는 질문에 대한 답이 모호하다.
GPT-1의 제안 방법
Architecture
- GPT-1은 Transformer의 디코더를 가져와 사용한다.
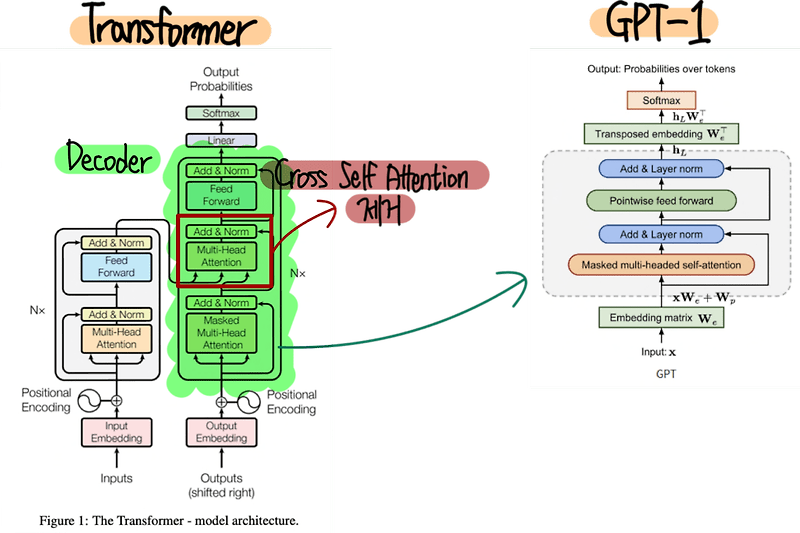
- 다음 그림과 같이 디코더를 가져오지만 인코더가 없기 때문에 Encoder-Decoder Attention 블럭은 없이 진행한다.
- 또한, Transformer와 달리 디코더 출력 이후 Linear 계층을 통과하는 것이 아니라 Transposed Embedding으로 input embedding에 쓰인 행렬을 전치화하여 벡터를 다시 단어로 만드는 작업을 시행한다.
- GPT-1은 총 12개의 디코더를 통과하여 최종 출력을 만든다.
Unsupervised Pre-Training (Next Word Prediction)
- GPT-1에서 부터 GPT-4까지 OpenAI가 고집스럽게 이어오는 전통 철학이 바로 Unsupervised Pre-Training 방법이다.
- GPT-1은 다음 단어를 학습하는 방식으로 비지도 학습을 시행한다.
- 이러한 비지도 학습에는 다음과 같은 손실함수가 사용된다.
-
$L_1(u) = \sum\limits_{i}\log P(u_i u_{i-k}, \cdots , u_{i-1};\theta)$ - $u = {u_1, \cdots , u_n}$ ; 토큰들의 집합
- $k$ = size of context window
- $\theta$ = model parameters
-
- 해당 손실 함수는 다음 단어가 올 확률을 나타내는데 다음과 같은 예시를 들 수 있다.
- 만약 입력되는 문장이 “나는 오늘 학교에 간다” 이고 이중에서 “나는 오늘 학교에” 라는 것을 입력으로 넣으면 출력으로 다음 단어인 “간다”가 나올 확률이 $L_1$이 되는 것이다.
- 이러한 비지도 학습 방식을 도입하면 Unlabeled Dataset을 가지고도 효과적인 학습이 가능하다.
Next Word Prediction의 효과
- 그래서 Next Word Prediction이 어떻게 기존의 문제점은 해결한 것인가?
- Next Word Prediction은 다음과 같은 장점을 가지고 있다.
- 자연스러운 언어 구조의 학습
- 다음 단어를 예측하며 자연스레 언어의 기본적인 구조와 문법을 학습하게 된다.
- 문맥에 대한 이해
- 앞의 내용을 이해해야 다음 단어를 원활히 예측하기 때문에 문맥에 대한 이해도 학습하게 될 것이다.
- 다양한 언어 패턴 학습
- 인터넷에서 긁어모은 Unlabeled Dataset은 다양한 언어와 패턴들을 가지고 있기 때문에 다양한 언어 패턴이 학습될 것이다.
- 전이 학습의 유용함
- 전이 학습은 Pre-Trained 모델을 기반으로 fine-tuning을 진행해야하는데 여러 분야에 맞는 fine-tuning이 될려면 pre-trained가 다양한 분야에 적합한 형태로 이루어져야한다.
- 다음 단어를 예측하는 것은 특정 분야에 치우치지 않고 학습이 가능하기 때문에 전이 학습에 매우 유용하다.
- 자연스러운 언어 구조의 학습
Supervised Fine-Tuning
- Unsupervised Learning으로 Pre-Trained 모델을 학습시키고 나면 원하는 분야의 Labeled Dataset을 가지고 Supervised Fine-Tuning을 시작한다.
- 해당 Labeled Dataset이 $C$라고 가정할 때 손실 함수는 다음과 같이 나타낸다.
-
$L_2(C) = \sum\limits_{(x,y)}\log P(y x^1, \cdots, x^m)$
-
- 또한, 각 분야에 맞는 출력을 얻을 수 있게 Pre-Trained 모델에서 최종 linear 출력층을 추가한다. 즉, 최종 출력은 다음과 같은 연산을 통해 계산된다.
-
$P(y x^1, \cdots, x^m) = softmax(h^m_lW_y)$ - $h^l_m$ = Pre-Trained 모델의 최종 hidden state
- $W_y$ = Fine-Tuning의 최종 출력을 위한 Linear 층의 Weight
-
- 마지막으로 논문에선 Auxiliary objective라고 해서 비지도 학습에서 쓰이는 손실 함수도 추가하여 최종 Fine-Tuning을 위한 손실 함수를 만든다.
- $L_3(C) = L_2(C) + \lambda L_1(C)$
- $\lambda$ = hyperparameter
- $L_3(C) = L_2(C) + \lambda L_1(C)$
- 최종적으로는 Fine-Tuning을 위해서는 최종 출력을 위한 $W_y$와 인풋에 따라 추가되는 delimiter의 임베딩 행렬외에는 추가되는 파라미터는 없다.
Task-Specific Input Transformation
- 여러 분야로 Fine-Tuning을 하기 위해서는 그에 맞는 Input Structure가 필요하다.
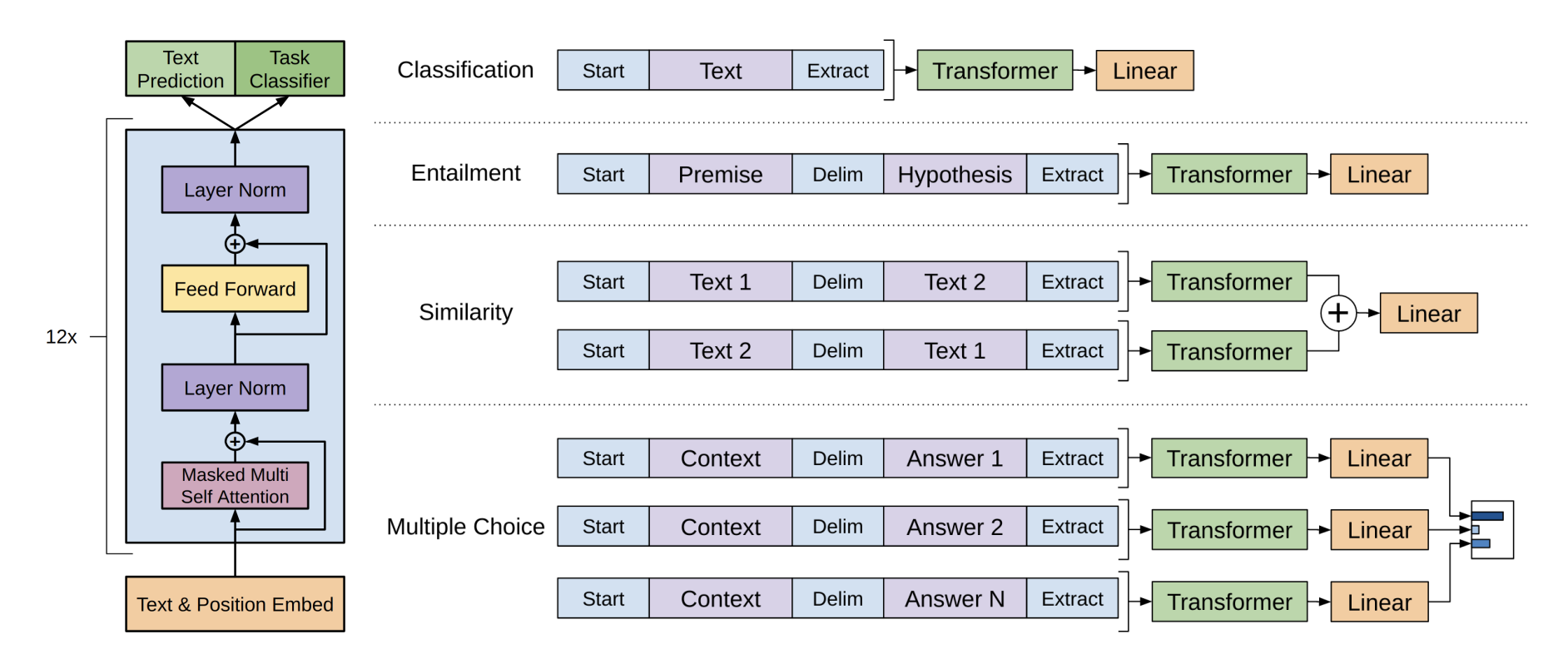
- Classification
- 이 경우 그냥 문장 자체를 인풋으로 넣으면 된다.
- Entailment
- 문장 사이의 관계를 예측하는 Entailment 문제의 경우 전제와 가설을 $를 delimiter로 사용하여 Input을 만든다.
- Similarity
- 유사도 같은 경우 문장 2개의 순서의 상관 없이 예측을 해야하기 때문에 순서를 뒤바꿔 2개의 Input을 넣어준다.
- Multiple Choice
- 이 경우 선택지의 수 만큼 Input을 늘려줘야한다.