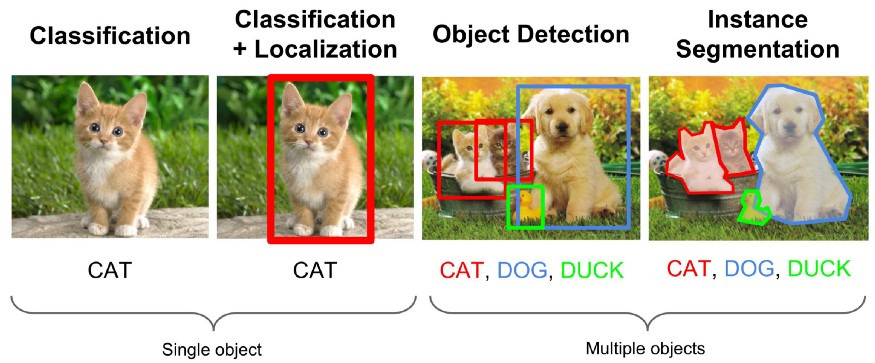
Concepts of Object Detection
Object Detection 개념 정리
Object Detection이란?
Object Detection 직역하자면 객체 구분 정도로 번역할 수 있다.
Object Detection은 우리가 CNN 논문 정리하며 배웠던 classification과 localization이라는 개념이 합쳐진 개념인데 이를 완전히 이해하기 위해서는 우선 localization에 대해서 알아야한다.
Classification & Localization
Classification은 식별 과정이며 들어온 이미지를 보고 주어진 class 중에 어떤 class에 해당하는 지를 구별해내는 과정이다.
예를 들어 강아지 사진이 입력으로 들어왔으면 강아지라는 출력이 나와야 되는 것이다. (물론 정석대로 말하자면 softmax 함수를 통과하기에 강아지일 확률이 가장 높게 나와야 된다.)
그렇다면 localization은 무엇일까?
Localization은 객체의 위치를 특정해주는 작업을 말한다.
무엇이든 일단 객체라고 인지하면 객체를 감싸는 Bounding Box의 좌표를 반환해야한다.
보통 Bounding Box를 반환한다고 하면 좌측 상단 혹은 우측 하단의 x, y좌표와 BBox의 높이와 너비 값 (총 4개의 값)을 리턴한다.
Object Detection
Classification과 Localization을 동시에 진행하면 단일 객체에 대한 작업이 이루어지는 것이고 이제 복수 개체에 대해 classification과 localization을 해내는 것이 Object Detection이다.
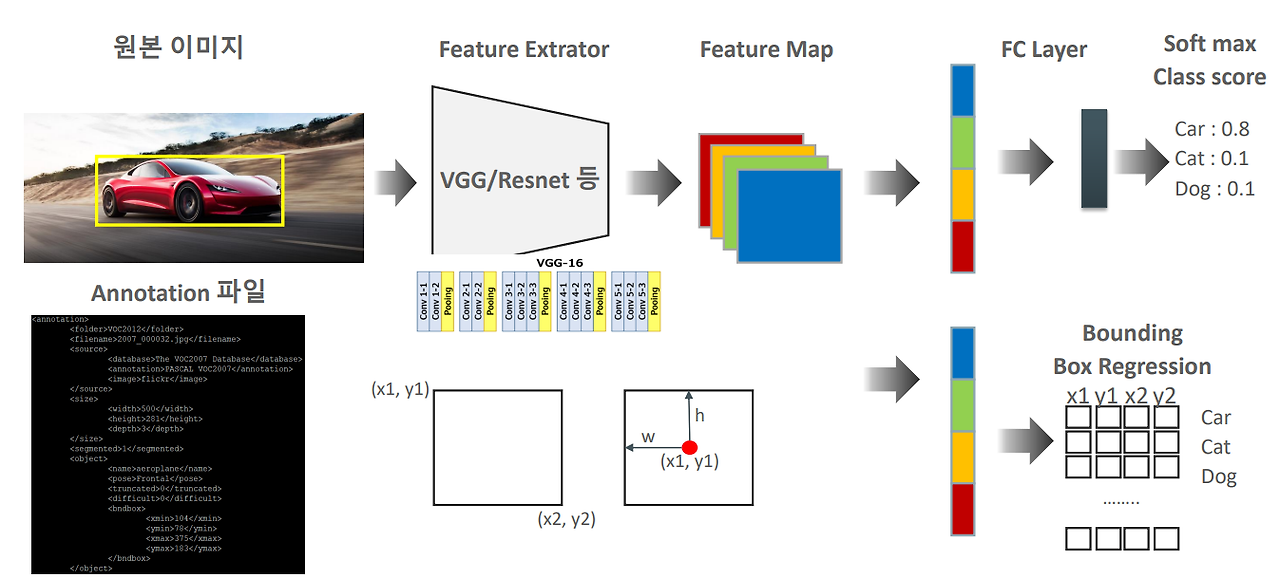
Classification + Localization의 구현 방법
Classification 같은 경우 흔히 알듯 CNN을 통해 입력 이미지에 대한 Feature Map을 얻은 다음 flatten을 하여 FC Layer에 통과시키는 방식으로 이미지에 대한 class를 식별해낸다.
Localization은 여기에 Bounding Box의 좌표도 예측하는 부분도 추가하여 학습시키면 구현이 완료된다.
구현 방식의 문제점
위와 같은 구현 방식은 단일 객체에 제한된다. 왜냐하면 CNN을 통해 feature map을 도출해내면 단일 객체에 대해서는 feature를 뽑아내기 쉬울 것이다.
하지만 복수 개체에 대해 feature map을 도출해내면 단순 CNN 만으로는 해내기 어려운 작업이다.