3-5. Stochastic Gradient Descent (SGD)
GD vs. SGD
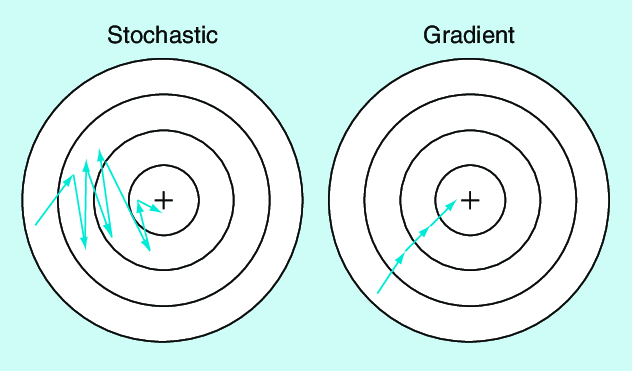
- SGD는 전체 데이터에 대한 Loss를 보고 그라디언트를 구하는 것이 아니라 데이터의 일부에 대한 Loss만을 보고 판단한다.
- 데이터의 일부가 아니라 데이터 한개만 보고 판단을 하고 비복원추출(w/o replacement)을 통해 손실 값을 계산한다.
- 모든 데이터를 사용하여 손실을 계산했으면 다시 처음부터 비복원추출을 실시한다.
- 즉, GD보다 빠르게 방향을 결정할 수 있다.
- 근데 왜 그라디언트가 최적의 방향으로 향하지 않을까?
- 일부 데이터에 대한 Loss에 대한 그라디언트 이기 때문에 전체 데이터 Loss에 대한 최적점을 향하지 않는다.
- 하지만 이런 부분 덕분에 Local Minimum에서 빠져나올 수 있는 기회가 만들어지기도 한다.
- 위의 그림을 보면 SGD가 GD보다 업데이트 횟수가 많은데 왜 SGD가 빠른가?
- 물론 업데이트 횟수는 더 많지만 SGD는 일부 데이터에 대한 Loss만을 계산하기에 그라디언트 계산 속도가 더 빠르다. 결국 종합적으로는 SGD가 속도가 더 빠르게 최적점에 다다른다.