9-3. Seq2Seq
RNN 유형
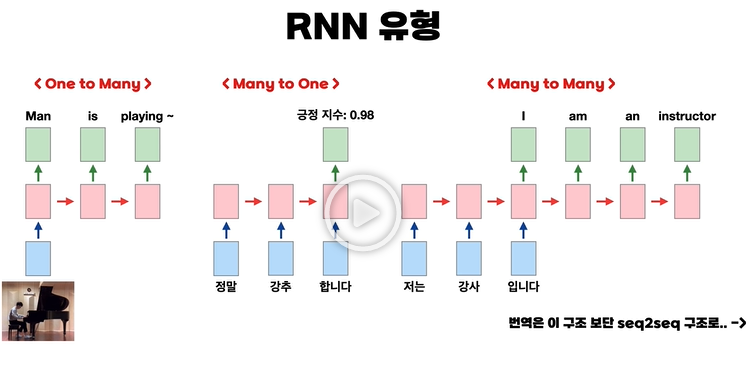
- RNN은 우리가 저번 강의에서 봤듯이 글자의 마지막 알파벳만 맞추는 형태로만 쓰일 수 있는 것이 아니다.
- One to Many
- 입력이 1개, 출력이 여러 개인 형태이다.
- 그림을 넣고 그림을 설명하는 문장을 출력하는 것이 예시이다.
- Many to One
- 입력이 여러 개, 출력이 1개인 형태이다.
- 어떠한 문장을 읽고 해당 문장의 감정 지수를 나타내는 것이 하나의 예시이다.
- Many to Many
- 입력이 여러 개, 출력도 여러개인 형태이다.
- 번역 같은 경우가 해당 예시이다.
- 해당 유형 같은 경우는 seq2seq라는 구조가 더 성능이 좋다.
seq2seq 개념
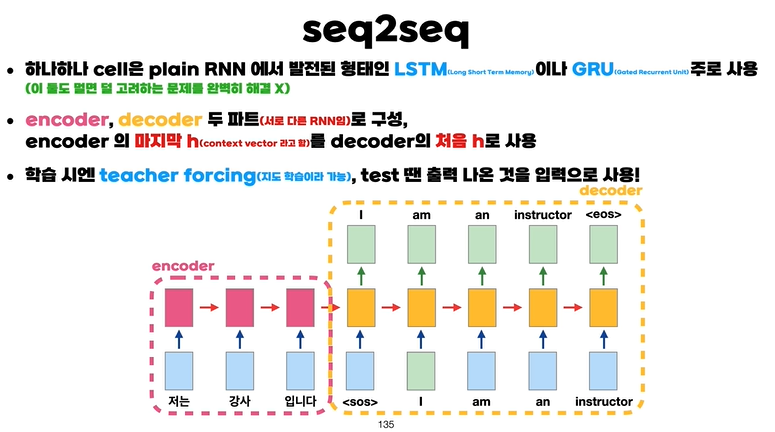
- seq2seq에서는 RNN과 달리 하나하나의 cell은 LSTM이나 GRU의 형태를 가지고 있다.
- LSTM(Long Short Term Memory)과 GRU(Gated Recurrent Unit)는 과거의 정보를 얼마나 가지고 올까라는 정보도 추가하여 이전의 정보가 잊혀지지 않게 해주는 형태이다.
- 하지만 해당 형태도 결국 멀어질수록 과거의 정보를 잊게 된다.
- Encoder와 Decoder의 두 파트로 구성이 되어있다.
- Encoder는 입력 문장을 받아서 출력 없이 계속 넘겨준다.
- 하지만 토큰 (start of sentence)를 넘겨주어 입력 문장의 끝과 decoder의 시작을 알려준다.
- 이후 decoder가 작동을 하면서 번역 문장을 출력한다.
- 이때 encoder에서의 마지막 $\vec h$를 첫 $\vec h$로 사용을 한다.
- 해당 벡터를 context vector 라고 한다.
- Decoder는 teacher forcing이라는 학습 방법을 사용한다.
- Decoder의 입력 데이터를 정답 데이터로 사용한다는 것이다.
- 테스트때에는 출력 데이터를 다음 셀의 입력 데이터로 사용한다.
- 즉, 만약 테스트때 첫 단추를 잘못 끼면 이후 도미노 처럼 출력 물이 망가지게 된다.
- 그리고 Encoder와 Decoder는 서로 다른 RNN 이기 때문에 다른 파라미터를 가진다.
- RNN에서 학습하는 파라미터는 대표적으로 $W_x, W_h$가 있는데 해당 파라미터는 인코더와 디코더에서 다른 값을 가지는 별개의 파라미터이다.
seq2seq의 문제점
- RNN의 고질적인 문제점이 해결되지 않았기에 이 형태 또한 멀수록 잊혀지는 문제점이 있다.
- context vector에는 입력의 마지막 단어의 정보가 가장 많이 들어있다. context vector만을 가지고 decoder가 작동을 하기 때문에 decoder는 마지막 단어를 가장 중점으로 보고 출력 값을 내놓는다.
파이썬 실습
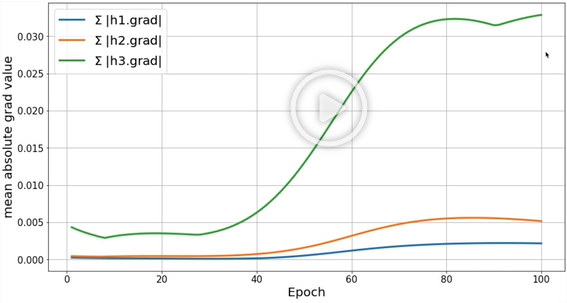
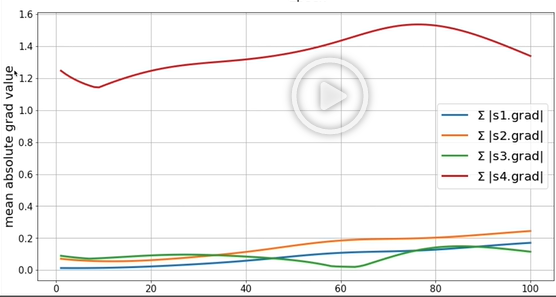
- 왼쪽이 encoder의 그라디언트, 오른쪽이 decoder의 그라디언트이다.
- 둘 다 보이다 싶이 멀어질수록 그라디언트가 줄어드는 것을 볼수가 있다.
- 특히나 왼쪽 그라디언트의 값을 보면 가장 큰 값이 0.003으로 거의 0에 수렴한다.