Overfitting & Data Augmentation
7-5. Overfitting & Data Augmentation
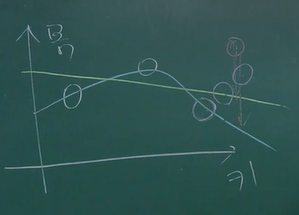
Overfitting (과적합)

- 좌측에 보이다싶이 과적합이란 모델을 너무 복잡하게 만들어서 실제 테스트 데이터가 들어왔을 때 예측 능력이 현저히 떨어지는 현상을 일컫는다.
- 초록색 예시는 단순한 모델이고 파란 색 예시는 인공 신경망을 깊게 만들었을때 나타나는 현상이다.
- 빨간 색으로 표시 된 새로운 데이터를 넣었을 때 파란 색이 훈련데이터에선 Loss가 0이었지만 새로운 데이터에선 Loss가 상당히 크다.
Overfitting의 해결방안
- 모델 경량화
- 관계를 너무 복잡하게 만들어서 overfitting이 일어난다. 즉, 모델의 층을 줄이고 노드의 수를 줄여서 모델 자체를 경량화 하는 방법이다.
- Data Augmentation (데이터 증강)
- 훈련 데이터 수 자체가 너무 적어서 overfitting이 일어나는 경우도 있다. 그래서 인위적으로 데이터를 늘리는 방법을 데이터 증강이라고 부른다.
Data Augmentation
-
파란 색으로 그려진 것이 원본 데이터이다. 다음과 같이 키가 크면 몸무게가 늘어난다 라는 가정하에 핑크 색으로 새로운 데이터를 만들어서 집어넣었다.
-
이것이 하나의 데이터 증강법 예시이다.
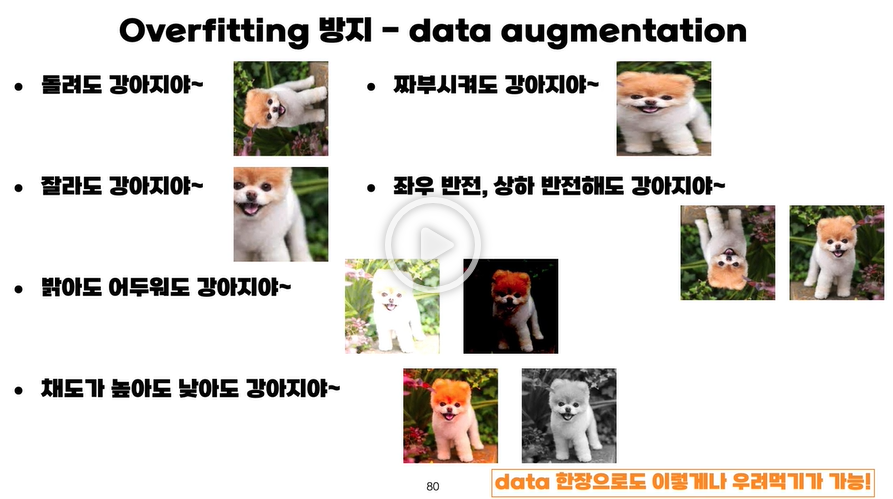
- 사진 데이터 같은 경우 위와 같이 단순한 변화를 주어도 우리가 인식할 때는 강아지라고 인식하기 때문에 변화 몇가지를 주어 1가지 데이터로도 수십가지의 인위 데이터를 만들어 낼 수 있다.