3-6. 미니 배치 SGD
SGD의 단점
- 너무 성급하게 방향을 결정한다.
- 데이터 하나만의 Loss을 보고 판단하기 때문.
- 이를 해결하기 위해 나온 방법이 미니 배치.
미니 배치 SGD
- 손실 값을 계산할 때 한 개의 데이터만 보는 것이 아니라 2개 이상의 데이터를 보고 손실 값을 계산하자는 개념이다.
- 2개 이상의 데이터의 뭉치를 미니 배치라고 말한다.
- Size of Mini Batch = 데이터의 갯수
- 예를 들어 5개의 데이터가 있는데 미니 배치 사이즈가 3이면 한개의 미니 배치를 가져가면 남은 2개의 데이터는 어떻게 하나?
- 답은 2개만을 사용하여 손실 값을 계산한다.
- 중점은 모든 데이터를 고려해야 되기 때문에 미니 배치 사이즈에 맞지 않더라도 마지막에 남은 데이터들은 한 개의 미니 배치로 사용한다.
- 또한 요즘은 GPU의 병렬 계산 능력이 상당히 발전했기 때문에 계산 속도가 상당히 빨라진다.
미니 배치 SGD의 단점
- 무작정 배치 사이즈를 키우면 모델의 성능이 너무 저하된다. 즉, 에러가 너무 커진다.
- 논문에 따르면 최대 사이즈는 8000정도가 적당한데 이에 대한 조건도 있다.
- Linear Scaling Rule: 배치 사이즈가 두배가 되면 학습률도 두배로 키워라. 즉, 비례되게 증가해야한다.
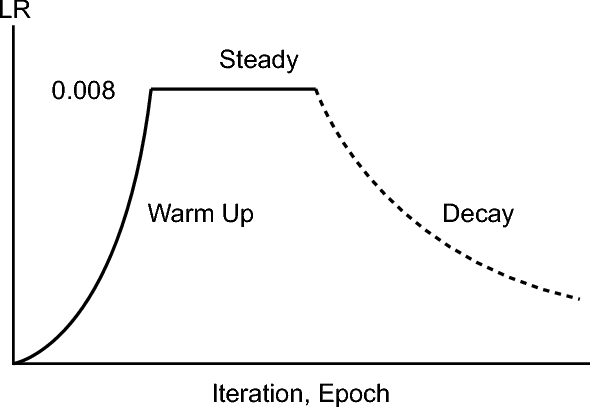
- LR Warm Up: 내가 정한 학습률이 만약 0.1이라면 학습 초반에는 더 작게 시작해서 천천히 0.1로 끌어올린 다음 0.1로 고정을 하든 스케줄링을 하든 하는 것.
Parameter vs. Hyper-parameter
- Parameter : 모델이 찾는 값
- Weight
- Bias (Weight에 포함되기도 함)
- etc.
- Hyper-parameter : 내가 정하는 변수
- Initial Weight
- Epoch
- Batch Size
- LR
- Model Architecture