Loss Landscape / Skip-Connection
7-4. Loss Landscape & Skip-Connection
ReLU & BN의 문제점
- BN과 ReLU의 콤비네이션으로 vanishing gradient를 해결해내었다.
- 하지만 이 둘의 콤비로 층을 더 깊게 만들면 underfitting의 문제가 일어난다.
- 다음 그림은 ResNet 논문에서 가져온 자료이다.
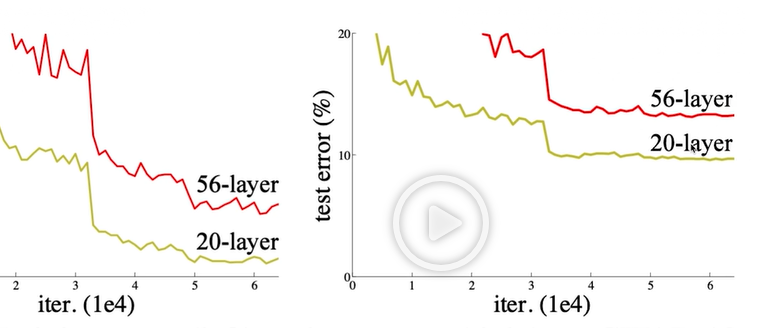
- 하지만 ResNet 논문 자체에서도 이에 대한 원인을 찾지 못하고 future work. 즉, 후일에 맡긴다고 하였다.
Skip-Connection
- 이후 위의 문제에 대한 해결 방안이 나왔는데 이는 skip-connection을 사용하는 것이다.
- 이 또한 정설은 아니지만 거의 정설처럼 받아들여지는 의견이다.
-
skip-connection이란?
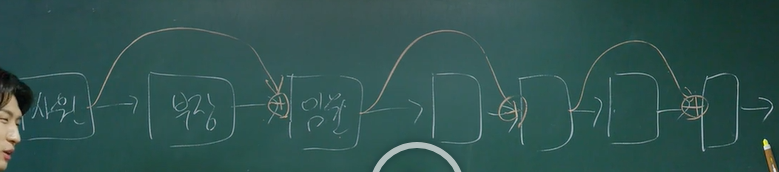
- 위와 같이 층마다 연결이 되는 신경망에서 한 층을 건너뛰고 값을 전달해주는 방법이다.
- 기업 직책에 비유를 해보자면 사원이 임원한테 바로 의견을 제시하는 것이다.
- 하지만 부장이 임원한테 전해주는 의견이 묵살되는 것이 아닌 사원의 의견과 합해져서 전달 되는 것이다.
-
Skip-connection을 적용했더니?
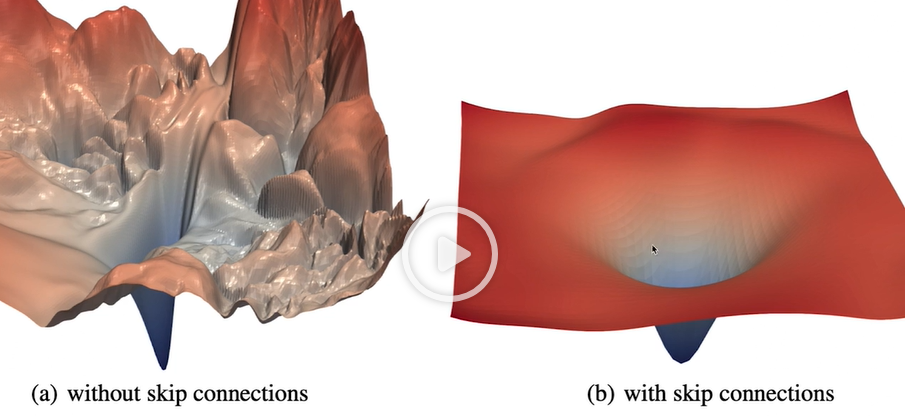
- 다음과 같이 Loss Landscape가 꼬불꼬불해지지 않고. 즉, non-convexity가 낮아지면서 convex한 loss landscape으로 변한다는 것이였다.
- 즉, local minimum에 빠질 확률이 줄어든다는 것이다.
Loss Landscape
- 그러면 드는 의문은 파라미터는 수백개 또는 수만개까지도 되는데 어떻게 3차원 상으로 Loss Function을 그려냈나? 이다.
- 이는 다음과 같은 방법을 사용했다.
- $\vec w = \begin{bmatrix}\vdots\end{bmatrix}$ 라는 n개의 가중치를 담고 있는 벡터가 있다고 가정하자.
- 그렇다면 가우시안 노이즈. 즉, 가우시안 분포에서 랜덤하게 뽑아낸 벡터 2개를 만든다. 이는 $\vec w$와 같은 사이즈다.
- 랜덤하게 뽑힌 벡터를 $\vec d_1, \vec d_2$라고 하자.
- Loss Landscape는 $L(\vec w+a\vec d_1+b\vec d_2)$에서 a와 b를 축으로 그려낸 것이다.
파이썬 실습
- 먼저 MNIST 데이터셋을 기반으로 CNN 모델을 구축한 후 층이 10개가 되도록 만든 후 모델을 돌려보았다.
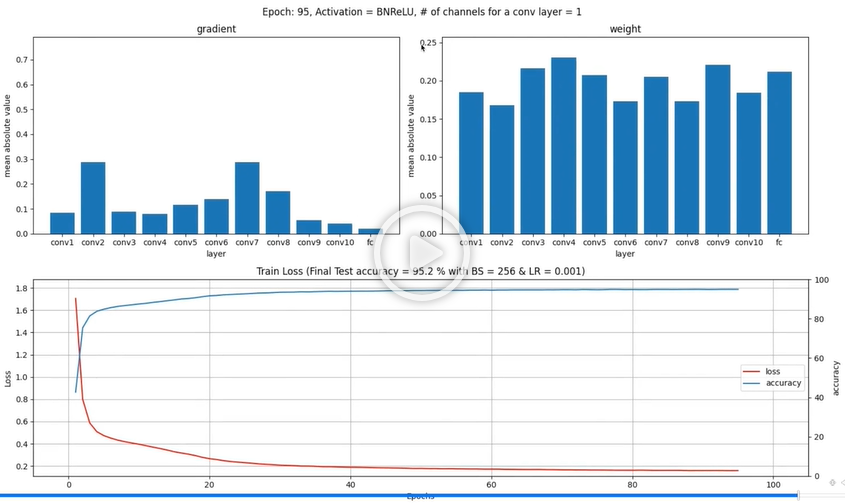
BN+ReLU w/ 10 layers
- 상당히 성능이 잘 나오는 것을 볼수 있다.
- 하지만 여기서 층을 100개로 늘리면 어떨까?
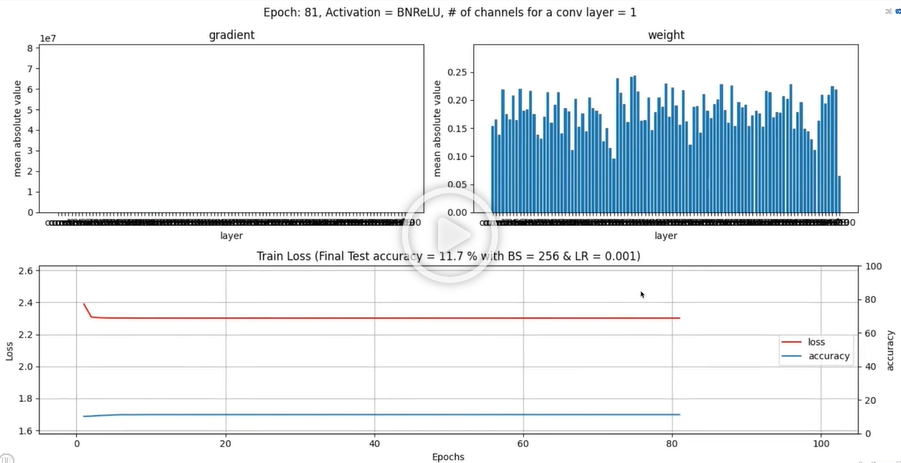
BN+ReLU w/ 100 layers
- 보다 싶이 성능이 매우 저하되어 Underfitting이 일어났다.
- 여기서 그라디언트의 차트를 보고 Vanishing gradient가 아닌가? 라고 생각할수도 있다.
- 하지만 사진에는 안나오지만 초반 에포크에서는 초반 레이어의 그라디언트의 값이 양호했다.
- Vanishing Gradient였으면 마지막 레이어의 그라디언트가 크고 점점 초반 레이어로 갈수록 그라디언트가 줄어드는 형태가 보였어야 한다.
- 각각의 상황의 Loss Landscape를 그려보면…
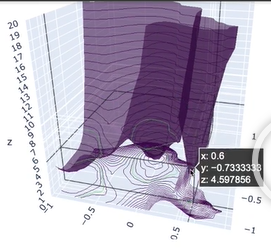
BN+ReLU w/ 10 layers
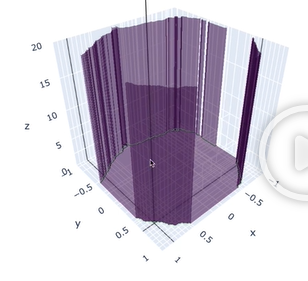
BN+ReLU w/ 100 layers
- 위와 같이 100개의 층을 가진 CNN은 어딜 빠져나갈수도 없이 한 구멍에 빠져버린다.
- 즉, 어떠한 학습이 되어도 Loss의 개선이 있을수가 없는 상황인 것이다.