3-10. K-fold Cross Validation
K-Fold Cross Validation
- K-Fold Cross Validation은 보통 데이터의 양이 너무 적어 Train의 일부를 validation으로 사용하기 어려울 때 사용되는 기법이다.
- 또한 shuffle을 하지 않고 validation set을 가져올 때는 편향된 데이터셋이 만들어질 수도 있기 때문에 K-Fold Cross Validation을 사용하기도 한다.
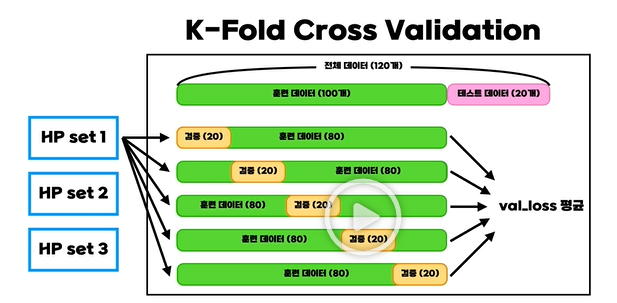
- 그렇기 때문에 위와 같이 여러 개의 validation set을 만들어서 각각의 loss의 평균을 내어 그것으로 성능을 측정한다.
- 평균 loss를 기준으로 여러 개의 하이퍼파리미터 세트를 시도해보고 하이퍼파라미터를 결정한다.
최종 모델 학습
- CV를 통해 정해진 하이퍼파리미터를 통해 validation set을 없애고 전체 훈련 데이터를 기반으로 모델을 새롭게 학습을 시켜 최종 loss값을 구하기도 한다.
- 다른 방법으로는 Fold로 나누어진 데이터셋을 그대로 두고 평균을 이용한다.
- 이때는 Majority Vote 즉, 다수결로 정하는데 예를 들어 3개의 데이터셋에서 1이라고 예측을 하고 나머지 2개가 0이라고 예측을 했으면 최종적으로 1이라고 예측을 하는 것이다.
- 위에서 말한 개념은 hard vote라고도 하는데 soft vote는 예측 값이 아니라 예측 확률 값의 평균을 사용해서 출력값을 결정한다.