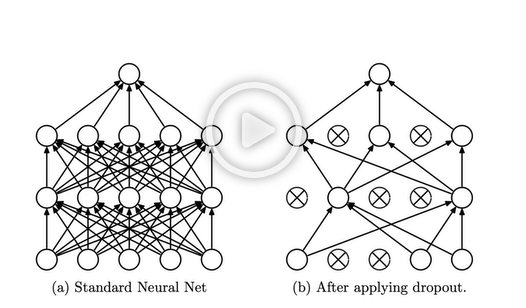
드롭아웃에 대한 확률은 각 노드별로 따로 지정해주는 것이 아니라 층 별로 드롭아웃을 적용할지 안할지를 정한 후 확률을 정한다. 이 확률은 해당 층에 있는 모든 노드에 적용이 된다.
그리고 위에 설명되어있듯이 데이터마다 확률에 따라 살릴 노드가 다시 골라진다. 즉, 데이터마다 single network가 생긴다는 뜻이다.
드롭아웃의 장점은 몇몇 노드를 없애며 훈련을 하다보니까 각각의 노드의 역할 분담이 잘 된다.
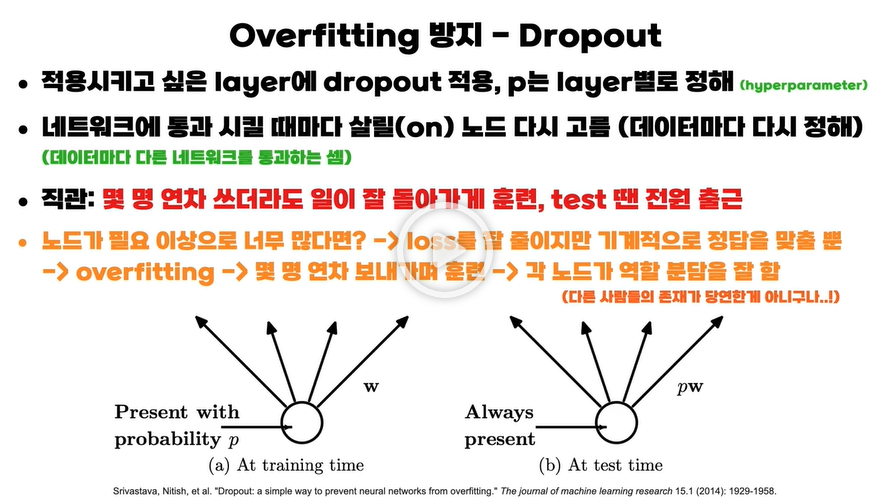
훈련 이후 테스트를 할 때에는 모든 노드를 살리는 대신 가중치에 아까 정했던 드롭아웃 확률 값이 곱해진다.
Dropout의 역할 분담
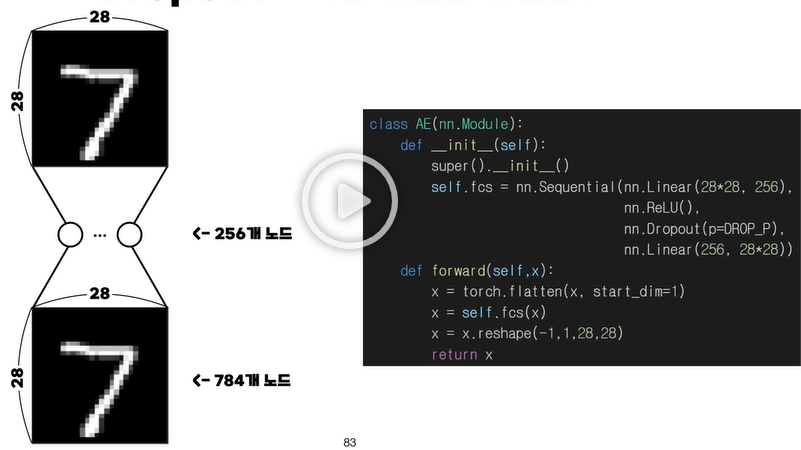
해당 예시는 AutoEncoder라고 불리는 모델이다.
해당 모델은 입력 사진 데이터를 한번 압축시키고 다시 복원시켜 출력시키는 작업을 한다.
PyTorch 같은 경우 nn.Dropout(p = DROP_P)라고 정의를 해주었는데 Dropout 논문에서는 p값이 노드를 살릴 확률로 정의 했지만 파이토치에서는 노드를 죽일 확률을 p라고 정의하였다.
그리고 드롭아웃 같은 경우 활성화 함수 이후에 적용을 시켜야한다.
파이토치에서는 노드 드롭아웃을 아예 노드 출력 값을 0으로 변환시켜 구현을 하기 때문에 활성화 함수 층 이후에 드롭아웃을 적용시켜야 한다.
드롭아웃을 적용시킨 결과물을 보면 사실 적용시키지 않은 결과물이 육안으로 봐도 훨씬 퀄리티가 좋게 나온 것을 알 수가 있다.
하지만 위의 Weight Map을 보면 매우 다르다는 것을 느낄 수 있다.
Weight Map이란 Autoencoder 예시에서는 784개의 입력 노드를 256개의 은닉 층 노드에 연결 시킨다. 이때 각각의 은닉 층 노드에는 784개의 입력 노드에 각기 다른 784개의 가중치가 곱해진 값이 들어갈 것이다. 즉, 위 그림에서는 784개의 가중치 값을 각각 256개의 노드마다 시각화 해놓은 것이다.
드롭 아웃이 적용된 Weight Map을 보면 각 노드가 어떠한 특징을 중요시 여기는 것을 볼 수 있지만 드롭아웃이 적용이 되지 않은 모델은 특정 특징을 잡아내는 것을 볼 수가 없다.
즉, 드롭아웃을 적용 할 시 노드가 역할 분담을 잘한다는 것을 알 수가 있다.
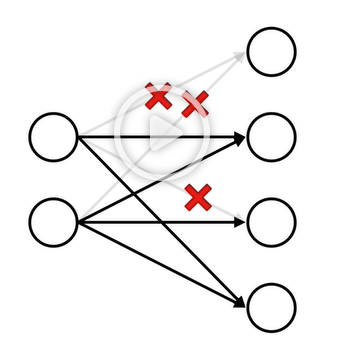
Dropconnect
Dropconnect는 Dropout과 달리 노드 자체를 없애는 게 아니라 노드와 노드 사이의 connection을 없애는 것이다.